
混合模型(hybrid model)是幾種不同模型組合而成的一種模型。它允許一個項目能沿著最有效的路徑發展。也可定義為由固定效應和隨機效應(隨機誤差除外)兩部分組成的統計分析模型。如由幾個高斯分布混合起來的模型叫高斯混合模型,幾個線性模型混合在一起的模型叫線性混合模型。一般的,被模擬的系統幾乎不可能按照一種模式一步一步地進行,會受到很多外界因素的干擾。而混合模型能夠適應不同的系統和不同情況的需要而提出一種靈活多樣的動態方法。混合模型分為分析、綜合、運行和廢棄四個階段,各階段的重疊為設計員提出了模型選擇。
基本介紹
- 中文名:混合模型
- 外文名:hybrid model
- 別稱:過程開發模型
- 學科:統計學
- 分類:固定效應模型,隨機效應模型
概念,定義,分類,固定效應模型,隨機效應模型,特點,
概念
混合模型是一個統計模型,包含fixed effects和random effects兩種效應的混合。
在統計學中,混合模型是代表一個大群體中存在子群體的機率模型,不要求被觀察的數據集認同個人觀察屬於哪個子群體. 一般,混合模型符合代表大群體觀察結果的機率分布的混合分布. 然而,當有關問題的混合分布關係到大群體到其子群體的起源性質時,混合模型常被用來做統計推斷,關於小群體的性質,而沒有子群體的認同信息。
有些方法實現混合模型的步驟涉及到做子群體認同歸屬的假設到個人觀察結果(或者子群體的權重), 在這種情況下這些步驟可以看著是一類非監督學習或者聚類過程. 並不是所有的推斷過程都會涉及這些步驟。混合模型不應該與組合數據的模型混淆, 比如說 數據的一部分的和被約束到一個常數上。
定義
混合模型被定義為:
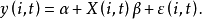
(i=1,2,...,N;t=1,2,...,T)
其中:
y(i,t)為北回歸變數(標量);
α為截距;
X(i,t)為k*1階回歸變數列向量(包括k個回歸量);
β為k*1階回歸係數列向量;
ε(i,t)為誤差項(標量).
分類
固定效應模型
套用前提是假定全部研究結果的方向與效應大小基本相同,即各獨立研究的結果趨於一致,一致性檢驗差異無顯著性。因此,固定效應模型用於各獨立研究間無差異,或差異較小的研究。
固定效應模型指實驗結果只想比較每一自變數項之特定類目或類別的差異及其與其他自變項之特定類目或類別間互動效果,而不想依此推論到同一自變項未包含在內的其他類目或類別的實驗設計。
隨機效應模型
隨機效應模型是經典的線性模型的一種推廣,就是把原來固定的回歸係數看作是隨機變數,一般都是假設來自常態分配。如果模型里一部分係數是隨機的,另外一些是固定的,一般就叫做混合模型。
隨機效應有壓縮的功能,而且可以使模型的自由度df變小。這個簡單的結果對現在的高維數據分析的發展起到了至關重要的作用。事實上,隨機效應模型就是一個帶懲罰項penalty的一個線性模型,引入正態隨機效應就等價於增加一個二次懲罰。著名的嶺回歸ridge regression就是一個二次懲罰,它的提出解決了當設計矩陣不滿秩時最小二乘估計LSE無法計算的問題,並提高了預測能力。
因此,引入隨機效應或者二次懲罰就可以處理當參數個數p大於觀測個數n的情形,這是在分析高維數據時必須面對的問題。當然,二次懲罰還有一些特點,如:計算簡便,能選擇相關的predictor,對前面的幾個主成分壓縮程度較小等。
特點
混合模型的特點是:無論對任何個體和界面,回歸係數α和β都相同。如果模型是正確假定的,解釋變數與誤差項不相關,即cov(X(i,t),ε(i,t))=0,那么無論是N趨於無窮還是T趨於無窮,模型參數的混合最小二乘估計量pooled OLS都是一致估計量。
