
基本介紹
- 中文名:固定效應模型
- 外文名:fixed effects model
- 簡稱:FEM
- 學科:數學
- 屬於:面板數據分析方法
- 相關概念:隨機效應模型、混合效應模型
簡介,分類,於隨機效應模型的比較,從定義的角度,基於統計學角度,基於權重分配的角度,
簡介
在面板數據線性回歸模型中,如果對於不同的截面或不同的時間序列,只是模型的截距項是不同的,而模型的斜率係數是相同的,則稱此模型為固定效應模型。除了固定效應模型,典型的面板數據分析方法還有隨機效應模型和混合效應模型。固定效應模型(FEM)假設所有的納入研究擁有共同的真實效應量,而隨機效應模型(REM)中的真實效應隨研究的不同而改變。基於不同模型的運算,所得到的合併後的效應量均數值也不相同。早在1976年,第一篇Meta分析就使用FEM進行了數據合併,基於其統計簡潔性及異質性認知,致使FEM廣泛使用,直到2006年仍然有四分之三的Meta分析的文章在使用。然而,隨著方法學不斷更新及異質性理解,方法學家們對於證據合併內在結構理解與剖析,已開始逐漸對“理想”狀態的FEM產生疑問。隨後,REM逐漸被使用,並替代部分FEM。
分類
固定效應模型可分為三類:
(1)個體固定效應模型:個體固定效應模型是對於不同的時間序列(個體)只有截距項不同的模型:

從時問和個體上看,面板數據回歸模型的解釋變數對被解釋變數的邊際影響均是相同的,而目除模型的解釋變數之外,影響被解釋變數的其他所有(未包括在回歸模型或不可觀測的)確定性變數的效應只是隨個體變化而不隨時間變化。
(2)時點固定效應模型:時點固定效應模型就是對於不同的截面(時點)有不同截距的模型。如果確知對於不同的截面,模型的截距顯著不同,但是對於不同的時間序列(個體)截距是相同的,那么應該建立時點固定效應摸型:

(3)時點個體固定效應模型:時點個體固定效應模型就是對於不同的截面(時點)、不同的時間序列(個體)都有不同截距的模型。如果確知對於不同的截面、不同的時間序列(個體)模型的截距都顯著不相同,那么應該建立時點個體固定效應模型:

於隨機效應模型的比較
從定義的角度
FEM:假設所有納入的研究擁有共同的真實效應量,或者除了隨機誤差外,所觀察效應量均為真實效應量。如比較對糖尿病黃斑水腫(DME)的抗血管內皮生長因子(Anti-VEGF)藥物中aflibercept與bevacizumab療效,除了藥物自身療效外,其他患者背景、藥物使用情況及測量結局的工具等均“一致”,每個研究的觀察效應量差別僅僅是由於抽樣誤差引起,也就是說,每個研究的觀察效應量就“等於”其真實效應量。Cochrane Handbook已明確指出,當異質性小於40%,建議採用FEM進行Meta合併,因此,FEM對各研究背景較為苛刻,僅適用於“理想化”研究背景。
REM:如上所訴,FEM中假設所有研究的真實效應量是相同的,但在大多數的系統評價和Meta分析中這是很難實現的。因為研究的對象很難保存同質性,所以在REM中的真實效應量會隨著不同的研究所改變,例如一個研究的效應量可能比擁有不同年齡、教育背景、健康程度等參與者的研究的效應量更高或更低,所以真實效應量的大小不僅取決於樣本的抽樣誤差,還取決於參與者或研究對象以及進行的干預措施等,也可稱其為異質性。
基於統計學角度
FEM:假設納入研究擁有共同的真實效應量,如圖1中圓圈所示,各研究合併的真實效應量(θ)用倒三角表示。可以發現,對於FEM,所有研究真實效應量都是相同的。每個研究的樣本量並非無限的,所以都會存在抽樣誤差(ε),從而導致了各研究的觀察效應量(Y)不等於真實效應量(如圖2中正方形所示),並且隨著研究的不同而不同,可以用公式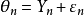 表示。
表示。 圖1
圖1
圖1REM:在圖3中,由於每個研究人群的背景、年齡、教育程度、地理環境的因素的不同,導致各個真實效應量也完全不同(成常態分配),同時也不同於合併的真實效應量(μ),把兩者之間的差值叫做真實差值,並用ζ表示(如圖4)。由於抽樣誤差的成在,相互之間的觀察效應量或多或少於真實效應量,例如圖4中的Study3,觀察效應量小於真實效應量,而真實效應量又小於合併的真實效應量,所以在REM中,合併後的真實效應量由兩種因素決定,即真實差值和抽樣誤差,可用下列公式表示。 圖2
圖2 圖3
圖3 圖4
圖4
圖2圖3圖4基於權重分配的角度
在Meta分析中,為了減少誤差獲得更加準確的結果,每種模型的計算各不相同,主要體現在各個研究權重值的分配上,這也是兩種效應模型的根本的區別所在。
FEM:在這種模型中,權重的分配主要依賴其精確度,每個研究的權重等於方差的倒數(W=1/V),樣本量越大,效應量的方差就越大,那么相應的權重分配就越多。因此大樣本的研究對總合併後效應量的貢獻值相對於小樣本研究就更大,導致小樣本研究更容易被忽略,分配的權重也就更少。
REM:與FEM不同,REM的總效應量是各個研究真實效應量的均數值,並非只注重大樣本量的研究,而是為了平衡每個研究的效應量注重所有納入的研究。
