")
標準差(Standard Deviation) ,中文環境中又常稱均方差,是離均差平方的算術平均數的平方根,用σ表示。標準差是方差的算術平方根。標準差能反映一個數據集的離散程度。平均數相同的兩組數據,標準差未必相同。
基本介紹
- 中文名:標準差
- 外文名:Standard Deviation
- 分類:數學
- 又名:均方差
- 功能:測量統計分布程度
- 相關:標準差
計算公式,公式意義,離散度,極差,離均差平方和,方差,標準差意義,變異係數,解釋,標準差標準誤,函式,外匯術語,套用實例,選基金,股市分析中,企業中的套用,
計算公式
標準差(StandardDeviation),在機率統計中最常使用作為統計分布程度(statisticaldispersion)上的測量。標準差定義是總體各單位標準值與其平均數離差平方的算術平均數的平方根。它反映組內個體間的離散程度。測量到分布程度的結果,原則上具有兩種性質:
簡單來說,標準差是一組數據平均值分散程度的一種度量。一個較大的標準差,代表大部分數值和其平均值之間差異較大;一個較小的標準差,代表這些數值較接近平均值。
例如,兩組數的集合{0,5,9,14}和{5,6,8,9}其平均值都是7,但第二個集合具有較小的標準差。
標準差可以當作不確定性的一種測量。例如在物理科學中,做重複性測量時,測量數值集合的標準差代表這些測量的精確度。當要決定測量值是否符合預測值,測量值的標準差占有決定性重要角色:如果測量平均值與預測值相差太遠(同時與標準差數值做比較),則認為測量值與預測值互相矛盾。這很容易理解,因為如果測量值都落在一定數值範圍之外,可以合理推論預測值是否正確。
標準差套用於投資上,可作為量度回報穩定性的指標。標準差數值越大,代表回報遠離過去平均數值,回報較不穩定故風險越高。相反,標準差數值越小,代表回報較為穩定,風險亦較小。
例如,A、B兩組各有6位學生參加同一次語文測驗,A組的分數為95、85、75、65、55、45,B組的分數為73、72、71、69、68、67。這兩組的平均數都是70,但A組的標準差約為17.08分,B組的標準差約為2.16分,說明A組學生之間的差距要比B組學生之間的差距大得多。
如是總體(即估算總體方差),根號內除以n(對應excel函式:STDEVP);
如是抽樣(即估算樣本方差),根號內除以(n-1)(對應excel函式:STDEV);
因為我們大量接觸的是樣本,所以普遍使用根號內除以(n-1)。
公式意義
所有數減去其平均值的平方和,所得結果除以該組數之個數(或個數減一,即變異數),再把所得值開根號,所得之數就是這組數據的標準差。
深藍區域是距平均值小於一個標準差之內的數值範圍。在常態分配中,此範圍所占比率為全部數值之68%。對於常態分配,兩個標準差之內(深藍,藍)的比率合起來為95%。對於常態分配,正負三個標準差之內(深藍,藍,淺藍)的比率合起來為99%。

離散度
標準差是反映一組數據離散程度最常用的一種量化形式,是表示精確度的重要指標。說起標準差首先得搞清楚它出現的目的。我們使用方法去檢測它,但檢測方法總是有誤差的,所以檢測值並不是其真實值。檢測值與真實值之間的差距就是評價檢測方法最有決定性的指標。但是真實值是多少,不得而知。因此怎樣量化檢測方法的準確性就成了難題。這也是臨床工作質控的目的:保證每批實驗結果的準確可靠。
雖然樣本的真實值是不可能知道的,但是每個樣本總是會有一個真實值的,不管它究竟是多少。可以想像,一個好的檢測方法,其檢測值應該很緊密的分散在真實值周圍。如果不緊密,與真實值的距離就會大,準確性當然也就不好了,不可能想像離散度大的方法,會測出準確的結果。因此,離散度是評價方法的好壞的最重要也是最基本的指標。
一組數據怎樣去評價和量化它的離散度,有很多種方法:
極差
離均差平方和
由於誤差的不可控性,因此只由兩個數據來評判一組數據是不科學的。所以人們在要求更高的領域不使用極差來評判。其實,離散度就是數據偏離平均值的程度。因此將數據與均值之差(我們叫它離均差)加起來就能反映出一個準確的離散程度。和越大離散度也就越大。
但是由於偶然誤差是成常態分配的,離均差有正有負,對於大樣本離均差的代數和為零的。為了避免正負問題,在數學有上有兩種方法:一種是取絕對值,也就是常說的離均差絕對值之和。而為了避免符號問題,數學上最常用的是另一種方法--平方,這樣就都成了非負數。因此,離均差的平方和成了評價離散度一個指標。
方差
由於離均差的平方和與樣本個數有關,只能反映相同樣本的離散度,而實際工作中做比較很難做到相同的樣本,因此為了消除樣本個數的影響,增加可比性,將離均差的平方和求平均值,這就是我們所說的方差成了評價離散度的較好指標。
樣本量越大越能反映真實的情況,而算術平均值卻完全忽略了這個問題,對此統計學上早有考慮,在統計學中樣本的均差多是除以自由度(n-1),它的意思是樣本能自由選擇的程度。當選到只剩一個時,它不可能再有自由了,所以自由度是n-1。
標準差意義
由於方差是數據的平方,與檢測值本身相差太大,人們難以直觀的衡量,所以常用方差開根號換算回來這就是我們要說的標準差。
在統計學中樣本的均差多是除以自由度(n-1),它是意思是樣本能自由選擇的程度。當選到只剩一個時,它不可能再有自由了,所以自由度是n-1。
變異係數
標準差能很客觀準確的反映一組數據的離散程度,但是對於不同的項目,或同一項目不同的樣本,標準差就缺乏可比性了,因此對於方法學評價來說又引入了變異係數CV。
一組數據的平均值及標準差常常同時做為參考的依據。在直覺上,如果數值的中心以平均值來考慮,則標準差為統計分布之一“自然”的測量。
定義公式:其中N應為n-1,即自由度
 標準差與平均值定義公式
標準差與平均值定義公式⒈方差s^2=[(x1-x)^2+(x2-x)^2+......(xn-x)^2]/(n)(x為平均數)
⒉標準差=方差的算術平方根errorbar。在實驗中單次測量總是難免會產生誤差,為此我們經常測量多次,然後用測量值的平均值表示測量的量,並用誤差條來表征數據的分布,其中誤差條的高度為±標準誤。這裡即標準差。
standarddeviation和標準誤standarderror的計算公式分別為
 標準差
標準差 標準誤
標準誤解釋
從幾何學的角度出發,標準差可以理解為一個從n維空間的一個點到一條直線的距離的函式。舉一個簡單的例子,一組數據中有3個值,X1,X2,X3。它們可以在3維空間中確定一個點P=(X1,X2,X3)。想像一條通過原點的直線。如果這組數據中的3個值都相等,則點P就是直線L上的一個點,P到L的距離為0,所以標準差也為0。若這3個值不都相等,過點P作垂線PR垂直於L,PR交L於點R,則R的坐標為這3個值的平均數:
 公式
公式運用一些代數知識,不難發現點P與點R之間的距離(也就是點P到直線L的距離)是|PR|。在n維空間中,這個規律同樣適用,把3換成n就可以了。
標準差標準誤
標準差與標準誤都是數理統計學的內容,兩者不但在字面上比較相近,而且兩者都是表示距離某一個標準值或中間值的離散程度,即都表示變異程度,但是兩者是有著較大的區別的。
首先要從統計抽樣的方面說起。現實生活或者調查研究中,我們常常無法對某類欲進行調查的目標群體的所有成員都加以施測,而只能夠在所有成員(即樣本)中抽取一些成員出來進行調查,然後利用統計原理和方法對所得數據進行分析,分析出來的數據結果就是樣本的結果,然後用樣本結果推斷總體的情況。一個總體可以抽取出多個樣本,所抽取的樣本越多,其樣本均值就越接近總體數據的平均值。
")
標準差表示的就是樣本數據的離散程度。標準差就是樣本平均數方差的開平方,標準差通常是相對於樣本數據的平均值而定的,通常用M±SD來表示,表示樣本某個數據觀察值相距平均值有多遠。從這裡可以看到,標準差受到極值的影響。標準差越小,表明數據越聚集;標準差越大,表明數據越離散。標準差的大小因測驗而定,如果一個測驗是學術測驗,標準差大,表示學生分數的離散程度大,更能夠測量出學生的學業水平;如果一個測驗測量的是某種心理品質,標準差小,表明所編寫的題目是同質的,這時候的標準差小的更好。標準差與常態分配有密切聯繫:在常態分配中,1個標準差等於常態分配下曲線的68.26%的面積,1.96個標準差等於95%的面積。這在測驗分數等值上有重要作用。
標準誤表示的是抽樣的誤差。因為從一個總體中可以抽取出無數多種樣本,每一個樣本的數據都是對總體的數據的估計。標準誤代表的就是當前的樣本對總體數據的估計,標準誤代表的就是樣本均數與總體均數的相對誤差。標準誤是由樣本的標準差除以樣本容量的開平方來計算的。從這裡可以看到,標準誤更大的是受到樣本容量的影響。樣本容量越大,標準誤越小,那么抽樣誤差就越小,就表明所抽取的樣本能夠較好地代表總體。
一個常態分配的總體,抽取n個作為樣本,可以得到樣本平均值,用樣本均值估計總體均值需要考慮樣本均值的方差或標準差(也就是標準誤)
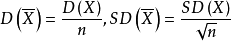
函式
Excel中有STDEV、STDEVP;STDEVA,STDEVPA四個函式,分別表示樣本標準差、總體標準差;包含邏輯值運算的樣本標準差、包含邏輯值運算的總體標準差(excel用的是“標準偏差”字樣)。
在計算方法上的差異是:樣本標準差^2=(樣本方差/(數據個數-1));總體標準差^2=(總體方差/(數據個數))。
函式的excel分解:
⑴stdev()函式可以分解為(假設樣本數據為A1:E10這樣一個矩陣):
stdev(A1:E10)=sqrt(DEVSQ(A1:E10)/(COUNT(A1:E10)-1))
⑵stdevp()函式可以分解為(假設總體數據為A1:E10這樣一個矩陣):
stdevp(A1:E10)=sqrt(DEVSQ(A1:E10)/(COUNT(A1:E10)))
同樣的道理stdeva()與stdevpa()也有同樣的分解方法。
外匯術語
標準差指統計上用於衡量一組數值中某一數值與其平均值差異程度的指標。標準差被用來評估價格可能的變化或波動程度。標準差越大,價格波動的範圍就越廣,股票等金融工具表現的波動就越大。
在excel中調用函式
“STDEV“
估算樣本的標準偏差。標準偏差反映相對於平均值(mean)的離散程度。
套用實例
選基金
在投資基金上,一般人比較重視的是業績,但往往買進了近期業績表現最佳的基金之後,基金表現反而不如預期,這是因為所選基金波動度太大,沒有穩定的表現。 基金的算法
基金的算法
基金的算法衡量基金波動程度的工具就是標準差(StandardDeviation)。標準差是指基金可能的變動程度。標準差越大,基金未來淨值可能變動的程度就越大,穩定度就越小,風險就越高。
比方說,一年期標準差是30%的基金,表示這類基金的淨值在一年內可能上漲30%,但也可能下跌30%。因此,如果有兩隻收益率相同的基金,投資人應該選擇標準差較小的基金(承受較小的風險得到相同的收益),如果有兩隻相同標準差的基金,則應該選擇收益較高的基金(承受相同的風險,但是收益更高)。建議投資人同時將收益和風險計入,以此來判斷基金。例如,A基金二年期的收益率為36%,標準差為18%;B基金二年期收益率為24%,標準差為8%,從數據上看,A基金的收益高於B基金,但同時風險也大於B基金。A基金的"每單位風險收益率"為2(0.36/0.18),而B基金為3(0.24/0.08)。因此,原先僅僅以收益評價是A基金較優,但是經過標準差即風險因素調整後,B基金反而更為優異。
另外,標準差也可以用來判斷基金屬性。據晨星統計,今年以來股票基金的平均標準差為5.14,積極型基金的平均標準差為5.04;保守配置型基金的平均標準差為4.86;普通債券基金平均標準差為2.91;貨幣基金平均標準差則為0.19;由此可見,越是積極型的基金,標準差越大;而如果投資人持有的基金標準差高於平均值,則表示風險較高,投資人不妨在觀賞奧運比賽的同時,也檢視一下手中的基金。
股市分析中
通過計算可以得到:
上證綜指業績期望值≈(110.93-0.13+8.94+17.24+43.86-15.34-20.82)/7=20.6685714
上證波動率期望值≈0.115643
標準普爾業績期望值≈6.731429
標準普爾波動率期望值≈0.068029
而標準差的計算公式則根據公式⑵計算: 分析圖2
分析圖2
分析圖2上證綜指的業績標準差≈45.2489073
上證波動率標準差≈0.063167
標準普爾指數業績標準差≈21.70647
標準普爾波動率標準差≈0.023647
因為標準差是絕對值,不能通過標準差對中美直接進行對比,而變異係數可以直接比較。計算可得:(變異係數C·V=(標準偏差SD÷平均值MN)×100%)
上證業績變異係數≈2.18926148
上證波動率變異係數≈0.5462
標準普爾業績變異係數≈3.2247
標準普爾波動率變異係數≈0.3476
企業中的套用
資本結構指的是企業各種資金來源的比例關係,是企業籌資活動的結果。最優資本結構是指能使企業資本成本最低且企業價值最大的資本結構;產權比率,即借入資本與自有資本的構成比例,是反映企業資本結構的重要變數。企業的資產由債務性資金和權益性資金組成,但其風險等級和收益率各不相同。根據投資組合理論,投資的多樣化可以分散掉一定的風險,因此資金提供者需要決定投資於債務性資金和權益性資金的比例。以便在權衡風險和收益的情況下保證其利益的最大化。理論探索而外部資金提供者利益的最大化也就是企業價值的最大化,這一投資比例對於企業融資而言也就是企業的最優資本結構比例。 分析圖
分析圖
分析圖假定某企業的資金通過發行債券和股票兩種方式獲得,並且都屬於風險性資產。σ其中債券的收益率為rD,風險通過標準差σD來衡量;股票的收益率為rE,風險為σE;股票和債券的相關係數為pDE,協方差為COV(rD,rE);債券所占的比重為wD,股票所占比重為WE(WD+WE=1)。根據投資組合理論,企業外部投資者對該企業投資所獲的期望收益率為E(rp)=WDE(rD)+wEE(rE),方差為
 方差
方差2、企業債務性資金和權益性資金完全負相關,即其相關係數為-1。投資者獲得的報酬率的期望值及其方差分別為。根據投資組合理論,只有當投資比例大於σE/(σD+σE)時其投資組合才是有效的。對於企業籌資而言,也即企業的權益性資金的比例大幹σE/(σD+σE),企業的籌資比例才是有效的,而且當組合比例為σE/(σD+σE)時,企業的籌資組合風險為零。
3、企業債務性資金和權益性資金的相關係數大於-1小於1。理論上,一個企業的兩種籌資方式之間的相關程度較高,一方面兩種籌資方式都承擔系統風險,另一方面它們也承擔相同的公司風險。因此從實踐來看,企業的不同籌資方式間的相關程度不可能是完全的正相關和負相關。對於一個企業而言,債務性資金對企業有固定的要求權,權益性資金對企業只有剩餘要求權,因此債務性資金的波動不可能像權益性資金的波動那么大。同時企業的風險會同時影響企業的債務性資金和權益性資金,因此企業的債務性資金和權益性資金的相關係數不可能為負數。企業不同的籌資方式間的相關係數一般在0-1之間。
那么究竟在什麼比例下企業的價值才會達到最大呢?根據投資組合理論,當E(r1)>E(r2),且
 方差3
方差3