基本介紹
- 中文名:最小描述長度
- 外文名:Minimum Description Length
- 學科:計算機
- 領域:計算機
描述,特徵,套用,相關概念,
描述
最小描述長度原則是將奧卡姆剃刀形式化後的一種結果。其想法是,在給予假說的集合的情況下,能產生最多資料壓縮效果的那個假說是最好的。它是在1978年由Jorma Rissanen所引入的。在資訊理論和計算機學習理論中,最小描述長度原則是個重要觀念。
任一資料集都可以由一有限(譬如說,二進制制的)字母集內符號所成的字串來表示。"最小描述長度原則背後的基本想法是:在任一給定的資料集內的任何規律性都可用來壓縮。亦即在描述資料時,與逐字逐句來描述資料的方式相比,能使用比所需還少的符號"(Grünwald, 1998。見底下的連結)。既然我們希望選取到的假說能抓到資料中最多的規律,於是我們則尋找壓縮效果最佳的假說。
若要如此,我們首先要決定一個用來壓縮資料的程式代碼。最一般的方式是選一個(具有圖靈完全特性的)計算機程式語言。我們接著以這個語言撰寫一個會輸出某筆資料的電腦程式。於是這個程式則能代表此筆資料。而能輸出此資料而又最短的程式,其長度被稱為此項資料的柯氏複雜性。這是Ray Solomonoff的核心概念,一個將歸納推論理想化後的理論。
然而,其想法在數學上並不提供一個實際的推論方法。最重要的理由如下:柯氏複雜度在計算理論中是不可計算的:不存在一個電腦程式,能在給予任意序列的資料情況下,輸出最短而又可以產生此筆資料的程式。即使我們偶遇一個最短的程式,一般情況下也無法確知它是最短的。柯氏複雜度與使用什麼電腦語言來描述程式有關。使用什麼語言是可任意選擇的,但一些額外的常數項會影響複雜度。基於這個理由,柯氏複雜度理論中傾向不理會常數項。但實務上,通常只有資料中的很小一部分總量是可得的,如此,則常數通常可以對於推論結果有很大的影響:好的結果不能保證能適用於有限的資料。
而最小描述長度原則則藉由以下方式來試圖補救上述問題:限制所能使用代碼的集合。使得對於所允許的代碼而言,尋找某筆資料最短的碼長變成可行(可計算)的。選擇一種代碼,使得不論手上有什麼樣的資料,此代碼在都是相當有效率的。這點是有些獨特的(exclusive),這方面則有許多研究在進行中。比起"程式",在最小描述長度理論的領域中,比較常用的是侯選假說、模型或代碼。允許使用的代碼集合則被稱為模型類別。(有些作者則模型類別指為模型,這會令人混淆)於是代碼描述及藉助於這代碼的資料描述的加總是最小的那個代碼會被選取。
特徵
最小描述長度的一個重要特性是,它提供了一個避免過適現象的保護裝置。這是因為它在假說複雜度和已知假說下的資料複雜度之間做了取捨。要理解為什麼這是對的,可以考慮以下的例子。假設你拋擲一個銅板一千次,且你觀察到了正反面的個數。我們考慮兩種模式類別:第一種是對每個結果,以0表正面及1表反面的方式來編碼。這代碼所代表的假說即為這銅板是公平。根據這個編碼方式所得的代碼長度總是1000位元。對於一個有偏向的銅板,第二個模型類別則是,所有有效率的代碼。其代表的假說即為這個銅板是不公正的。譬如,我們觀察到510個正面和490個反面。於是,根據第二個模型中最佳碼的所求得的碼長,應少於一千位元。因為這理由,一個天真的統計方法可能提出第二個假說應是對資料較好的解釋。然而,在一個最小描述長度策略中,我們必須基於假說建造一個單一碼,我們不能只是用最好的那一個。一個簡單的方式是,使用兩部分的代碼。我們先指定模型中哪一個假說擁有最佳的表現。然後指定使用這個代碼的資料。我們須要不少位元去指定哪一個代碼要使用。所以基於第二個模型的總碼長將大於一千位元。所以,如果你服從最小描述長度策略,其結論將是,即使第二個模型類別的最佳資料可以更適應資料,仍然沒有足夠的證據可以支持銅板是偏向的假說。
最小描述長度核心是代碼長度函式和機率分布之間的一對一且映成(牽涉到的引理為克拉夫特不等式)。 對於任意機率分布 P,去建造一代碼C,其長度為C(x)等於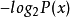 是可行的;這代碼最小化預期的碼長。反過來說,給予一個編碼C,則可以建造一個機率分布P,保持同樣的結果。(在這裡忽略rounding issues)。換句話說,搜尋一有效代碼被化簡化搜尋一個好的機率分布,反過來說亦如是。
是可行的;這代碼最小化預期的碼長。反過來說,給予一個編碼C,則可以建造一個機率分布P,保持同樣的結果。(在這裡忽略rounding issues)。換句話說,搜尋一有效代碼被化簡化搜尋一個好的機率分布,反過來說亦如是。
套用
如果將貝葉斯網路作為對實例數據進行壓縮編碼的模型, MDL原理就可以用於貝葉斯網路的學習。該度量被視為網路結構的描述長度和在給定結構下樣本數據集的描述長度之和。一方面,用於描述網路結構的編碼位隨模型複雜度的增加而增加 ; 另一方面, 對數據集描述的編碼位隨模型複雜度的增加而下降。因此,貝葉斯網路的 MDL總是力求在模型精度和模型複雜度之間找到平衡。構建貝葉斯網路首先定義一個評分函式, 該評分函式描述了每個可能結構對觀察到的數據擬合, 其目的就是發現評分最大的結構,這個過程連續進行到新模型的評分分數不再比老模型的高為止。
最小描述長度在分詞中的套用也比較直接,就是將分詞視為一種編碼方式,如一個字元串,”iloveyou“ ,總共8個符號,就是對應的8個字母,經過分詞後就是“i love you”,就只有3個符號,就是3個單詞,這樣總長度變小了,但是需要額外的信息來記錄單詞的信息,也就是模型。因此需要的總的長度不一定變小。
相關概念
透過上述的程式碼與機率分布之間的相似點,最小描述長度原理和機率論及統計學是有很密切的關連。這使得有些研究員將最小描述長度看成等同於Bayesian inference。模型的代碼長度和模型及資的料代碼長度則分別相當於Baysian架構中的prior probability和marginal likelihood。這觀點可用David MacKay的Information Theory, Inference, and Learning Algorithms中的例子來說明。(見下面連結)然而,當用Bayesian機器建造有效率 最小描述長度 程式碼有用時,最小描述長度 架構也包含其它非Bayesian的程式碼。一個例子是Shtarkov的'normalized maximum likelihood code',在目前 最小描述長度 理論中扮演一個核心角色。但不等於Bayesian推論。更進一步,Rissanen強調,對於真實資料產生過程,我們應該不做假設:實務上,一個model class在傳統上是真實的減化,所以不包含任何客觀角度都為真的程式碼或機率分布,根據 最小描述長度 哲學,如果Bayesian方法是基於對某於可能的資料產生過會導致不好結果的不安全的priors,我們應該除去。從 最小描述長度 的觀點來看,可接受的priors,通常傾向所謂的objvective Bayesian分析;然而,其動機通常是不同的。
最小描述長度並非第一個資訊理論來學習的策略。早在1968年,Wallace和Boulton即提倡一類似概念,稱作最小訊息長度。最小描述長度和最小訊息長度的不同一直是讓學界及百科編撰者困惑的來源。表面上來說,這些方法大致看似相同,但有一些主要不同,特別是在解釋方法上:
- 最小訊息長度是一個完全面向Bayesian策略:它從這個想法開始:一假說代表其在關於資料產生過程,以prior分布表示的可信度。最小描述長度公開地避免任何關於資料產生過程的假設(但請面上面關於選擇一個"合理"代碼的困難)。
- 兩種方法都使用了兩部分代碼:第一部分總是代表一人試圖去學習的資訊,如模型類別的索引(model selection)或參數值(估計理論)第二部分則是一種資料的編碼,在給予第一部分資訊的情況下。其不同是在於,在 最小描述長度 中,其建議,我們不想學到的參數應被移到第二部分的碼,其中他們可以使用one-part code來和資料在一起。這通常比two-part code更有效率。在 最小訊息長度 原始描述,所有的參數是在第一部分被編碼,所以會學到所有參數。
