
基本介紹
- 中文名:相似係數
- 外文名:similarity coefficient
- 取值範圍:(-1,1)
- 分類:關聯、距離、內積、信息、機率
簡介,選取原則,分類,關聯繫數,距離係數,內積係數,信息係數,機率係數,
簡介
相似係數是指衡量全部樣本或全部變數中任何兩部分相似程度的指標。它主要有匹配係數、內積和機率係數等項指標。由於內積係數是普遍套用於數量數據的相似性指標,因此,這裡僅對內積係數作一介紹。對於觀測數據矩陣X,一個樣本的數據可以認為是h維向量,同樣變數的數據也可以認為是多維向量。兩個同維向量的各分量依次相乘再相加得到一個數值,稱為兩向量的內積。
選取原則
相似係數的選取原則一般來說,同一批數據採用不同的相似性尺度,會得到不同的分類結果。產生不同結果的原因主要是由於不同的指標所衡量的相似程度的物理意義不同。也就是說,不同指標代表了不同意義上的相似性。因此,在進行數值分類時,應注意相似性尺度的選擇。一般情況下,應遵循下列基本原則:①所選擇的相似性尺度在實際套用中應有明確的意義。②如在變數分析中,常用相關係數表示變數之間的親疏程度。③根據原始數據的性質,選擇適當的變換方法,不同的變換方法涉及選用不同的相似係數。
分類
關聯繫數
按其係數取值在[0,1]和[-1,+1]之內,又分為兩類:匹配係數和關聯繫數。其計算都需要先列出被比較的兩實體(或屬性)的 列聯表。
列聯表。
有了列聯表中a,b,c,d的數值,這些係數的計算就容易了,列如匹配係數中的0chiai係數
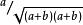
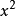
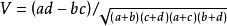

距離係數
距離係數由歐氏距離、弦距離、廣義距離等,但套用較多的是歐氏距離。計算公式為:
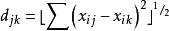
和

歐氏距離沒有確定的上界,受數據大小影響很大。若個屬性數據的量綱不同,大小相差懸殊,則可先對每個屬性用極差、離差或標準差等方法標準化,然後再求實體間的距離。
內積係數
一個實體的數據可認為是P維向量,同樣,屬性的數據也可認為是N維向量。兩個同維向量的各分量依次相乘相加,得到一個數值,稱為兩向量的內積或稱數量積。

信息係數
信息係數包括對稱的信息係數和非對稱的信息係數係數,這裡以對稱信息係數多狀態的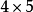 數據為例,說明如何判斷相似性的大小。
數據為例,說明如何判斷相似性的大小。
屬性/樣方 | A | B | C | ||
1 | 2 | 3 | 4 | 5 | |
1 | 2 | 1 | 1 | 1 | 1 |
2 | 3 | 2 | 2 | 1 | 4 |
3 | 1 | 3 | 3 | 2 | 2 |
4 | 2 | 4 | 4 | 4 | 1 |
依據上述數據,可以計算樣方B與樣方C間的信息相似係數,也可以計算樣方組A與樣方B間的信息相似係數,以及樣方組A與樣方C間的信息相似係數。信息相似係數的大小以兩個樣方或一個樣方與一個樣方合併後的信息增量的大小來表示。以組A總信息量為例來計算:
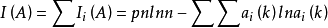
樣方B與樣方C間的信息相似係數為
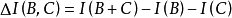
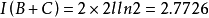
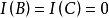

樣方組A與樣方間的信息相似係數為
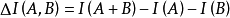
在樣方組A中,n=3,p=4;
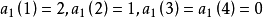
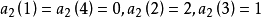
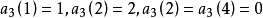
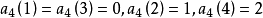
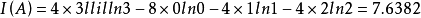
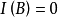
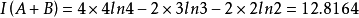
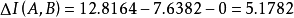
機率係數
Goodall提出一種依據機率的相似係數,對任何兩個實體的計算都要比較全部實體中所有可能實體對的數據。因此,它的數值與整個數據矩陣有關。
機率相似係數的取值在0與1之間。對於任何數據矩陣來說,必有一對樣方的相似係數近於1,表示它們最相似;也必有一對樣方近於0,表示它們最相異。
