一致估計亦稱相合估計和相容估計,是一種優良點估計。按收斂的意義不同將一致估計分為兩種:弱一致估計和強一致估計。
點估計又稱定值估計,是指直接用樣本平均數或樣本成數代替總體平均數或成數,而不考慮誤差的一種估計方法。例如對100名大學生進行收視率調查,調查結果是30%每天收看電視新聞,從而推斷, 在全體大學生中30%每天收看電視新聞。
基本介紹
- 中文名:一致估計
- 外文名:consistent estimator
- 領域:數學
- 學科:統計學
- 別稱:相合估計、相容估計
- 性質:點估計
概念,估計,點估計,區間估計,統計量,
概念
一致估計(consistent estimator)亦稱相合估計和相容估計。是一種優良點估計。設總體ξ的機率分布函式為F(x;θ),θ∈Θ為未知參數,若可估函式g(θ)估計量θ(ξ1,ξ2,…,ξn)當n趨於無窮時,在某種意義下收斂於g(θ),則稱θ(ξ1,ξ2,…,ξn)是g(θ)在這種收斂意義下的一致估計。它要求作為估計量的統計量,當樣本容量無限增大時,在某種意義下,收斂於待估計參數的真值。按收斂的意義不同將一致估計分為兩種:若當樣本容量n→∞時,對任意給定的ε>0,有:


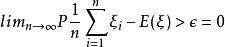
估計
根據觀測值來推測母體參數的值或範圍的過程稱為估計。估計分為點估計和區間估 計。點估計,是根據觀測值估計出對母體參數θ的估計值T(X1,X2,…… Xn) 的過程。例如,在進行燈泡壽命測定時,根據幾個燈泡壽命 來推測一批燈泡壽命的過程,就為點估計。其過程是: 先抽取若干個燈泡做樣本來測取壽命值 (以小時為單位) ,樣本的壽命分別是X1,X2,……Xn,求出平均值X=X1+X2+……Xn/n和方差:
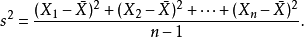
點估計
點估計又稱定值估計,是指直接用樣本平均數或樣本成數代替總體平均數或成數,而不考慮誤差的一種估計方法。例如對100名大學生進行收視率調查,調查結果是30%每天收看電視新聞,從而推斷, 在全體大學生中30%每天收看電視新聞。
一般說來,用抽樣指標估計總體指標,總會存在一定差異,但如果滿足下面3個要求,就可認為是合理估計或優良估計。1.無偏性。用抽樣指標估計總體指標時,個別樣本指標與總體指標間會有偏差,而用很多樣本指標的平均值估計總體指標,平均說來是無偏差的。2.一致性。用抽樣指標估計總體指標,當樣本單位數充分大時,抽樣指標將充分接近總體指標。3.有效性。用抽樣平均數和總體某一變數來估計總體平均數時,雖然兩者都是無偏估計量,但樣本平均數更靠近總體平均數,平均說來,它的離差較小,因此,是更優良的估計量。
區間估計
設總體或總體分布的某個參數為θ,從該總體抽取含量為n的樣本,按一定機率估計總體參數θ在哪個範圍,即由樣本觀測值求θ的1-α可信區間,1-α稱可信度,通常取95%可信度,即α=0.05,求θ的95%可信區間。如求總體均數μ的1-α可信區間,求總體率π的1-α可信區間,求總體回歸係數β的1-α可信區間等。θ的區間估計常和其點估計θ相結合。一般當樣本含量較大時(如n>30),θ近似服從常態分配,可用正態近似法求總體參數的1-α可信區間:

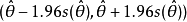
統計量
樣本的已知函式,其作用是把樣本中有關總體的信息匯集起來,是數理統計學中一個重要的基本概念。常用統計量有樣本矩、次序統計量、U統計量和秩統計量等。其中U統計量是W.霍夫丁於1948年引進的。統計量的充分性和完全性是兩個重要概念,充分性是費希爾在1925年引進的,內曼和P.R.哈爾莫斯在1949年嚴格證明了一個判定統計量充分性的方法,叫做因子分解定理。統計量的分布叫做抽樣分布,它的研究是數理統計中的重要課題。對一維正態總體,有三個重要的抽樣分布,即χ分布、t分布和F分布。其中χ分布是F.赫爾梅特於1875年在研究正態總體的樣本方差時得到的;t分布是英國統計學家W.S.戈塞特(筆名“學生”)於1908年提出的;F分布是費希爾在20世紀20年代提出的。
