
點估計(point estimation)是用樣本統計量來估計總體參數,因為樣本統計量為數軸上某一點值,估計的結果也以一個點的數值表示,所以稱為點估計。點估計和區間估計屬於總體參數估計問題。何為總體參數統計,當在研究中從樣本獲得一組數據後,如何通過這組信息,對總體特徵進行估計,也就是如何從局部結果推論總體的情況,稱為總體參數估計。
基本介紹
- 中文名:點估計
- 外文名:point estimation
- 又稱:定值估計
- 提出:К.皮爾森在1894年
- 學科:高等數學
- 來源:機率論與數理統計
概述,構造方法,估計法,參數估計,優良準測,小樣本優良性準則,大樣本優良性準則,
概述
當母群的性質不清楚時,我們須利用某一量數作為估計數,以幫助了解母數的性質。如:樣本平均數乃是母群平均數μ的估計數。當我們只用一個特定的值,亦即數線上的一個點,作為估計值以估計母數時,就叫做點估計。
構造方法
例如,若總體分布服從常態分配: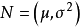 ,其中μ是總體均值,
,其中μ是總體均值,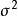 是總體方差,未知參數可記為θ=(μ,σ)。σ/μ(μ≠0)稱為變異係數,它是總體的一階原點矩(即均值)μ與二階中心矩(即方差)的函式。設有樣本X=(X1、X2…Xi),其一階樣本原點矩為,二階樣本中心矩為,而用估計 σ/μ,就是一個典型的矩估計方法。
是總體方差,未知參數可記為θ=(μ,σ)。σ/μ(μ≠0)稱為變異係數,它是總體的一階原點矩(即均值)μ與二階中心矩(即方差)的函式。設有樣本X=(X1、X2…Xi),其一階樣本原點矩為,二階樣本中心矩為,而用估計 σ/μ,就是一個典型的矩估計方法。
估計法
(1)最大似然估計法
此法作為一種重要而普遍的點估計法,由英國統計學家R.A.費希爾在1912年提出。後來在他1921年和1925年的工作中又加以發展。設樣本X=(X1,X2,…,Xn)的分布密度為L(X,θ),若固定X而將L視為θ的函式,則稱為似然函式,當X是簡單隨機樣本時,它等於ƒ(X1,θ)ƒ(X2,θ)…ƒ(Xn,θ),其中,ƒ(X,θ)是總體分布的密度函式或機率函式(見機率分布)。一經得到樣本值x,就確定x,然後使用估計g(θ),這就是g(θ)的最大似然估計。例如,不難證明,前面為估計常態分配中的參數μ和而提出的估計量和2,就是μ和的最大似然估計。
(2)最小二乘估計法
這個重要的估計方法是由德國數學家C.F.高斯在1799~1809年和法國數學家A.-M.勒讓德在1806年提出,並由俄國數學家Α.Α.馬爾可夫在1900年加以發展。它主要用於線性統計模型中的參數估計問題。貝葉斯估計法是基於“貝葉斯學派”的觀點而提出的估計法(見貝葉斯統計)。
參數估計
例如,設一批產品的廢品率為θ,為估計θ,從這批產品中隨機地抽出n個作檢查,以X記其中的廢品個數,用X/n估計θ,就是一個點估計。又如用樣本方差(見統計量)估計總體分布的方差,或用樣本相關係數估計總體分布的相關係數,都是常見的點估計。
優良準測
小樣本優良性準則
可以用來估計g(θ)的估計量很多,於是產生了怎樣選擇一個優良估計量的問題。首先必須對“優良性”定出準則。這種準則不是惟一的,它可以根據問題的實際背景和理論上的方便進行選擇。
若一個估計量抭(X)的數學期望等於被估計的g(θ),即對一切θ,則稱抭(X)為g(θ)的無偏估計,這種估計的特點是:在多次重複用時,抭(X)與g(θ)的偏差的算術平均值隨使用次數的增加而趨於零。因此,無偏性只在重複使用中,並且各次誤差能相互抵消時,才顯出其意義。
無偏估計並不總是存在。例如,設總體服從二項分布B(n,θ),0<;θ<1,則1/θ的無偏估計就不存在。有時,無偏估計雖然存在,但很不合理。在一些問題中,無偏估計有很多,它們的優良性由其方差來衡量,方差愈小愈好。若一無偏估計的方差比任何別的無偏估計的方差都小,或至多相等,則稱它為一致最小方差無偏估計。尋找一致最小方差無偏估計的一個普遍方法,是D.布萊克韋爾、E.L.萊曼和H.謝菲在1950年提出的,它基於統計量的充分性與完全性的概念:設抭(X)是一個無偏估計,T是一個完全充分統計量,則抭(X)在給定T時的條件期望就是一個一致最小方差無偏估計。克拉默-拉奧不等式是尋求一致最小方差無偏估計的另一重要工具,是由印度統計學家C.R.拉奧和瑞典統計學家H.克拉默在1945年和1946年先後獨立地證明的。當樣本的似然函式L(X,θ)滿足一定條件時,則 g(θ)的任一無偏估計 抭(X)的方差,對於一切θ滿足不等式這個不等式的右邊只與樣本的分布及待估函式 g有關,而與抭(X)無關。通常稱這個不等式為克拉默-拉奧不等式,或C-R不等式。它的右邊給出了 g(θ)的無偏估計的方差的最小下界,稱為克拉默-拉奧下界或C-R下界。因此,若某一無偏估計的方差達到上述C-R下界,則它必是一致最小方差無偏估計。C-R不等式在其他統計問題中也有套用。
在點估計問題中還使用其他一些小樣本準則,如容許性準則、最小化最大準則、最優同變準則(見統計決策理論)等。
大樣本優良性準則
(1)相合性
若g(θ)的估計量 抭n(X1、X2…Xn)在n趨於無窮時,在某種收斂意義下(見機率論中的收斂)收斂於g(θ),則稱抭n(X1,…,Xn)是 g(θ)的在這種收斂意義下的相合估計。這是點估計最基本的大樣本準則。例如依機率收斂意義下的相合性稱為弱相合,幾乎必然收斂意義下的相合性稱為強相合。矩估計一般具有相合性。最大似然估計在一定條件下為強相合的證明始自A.瓦爾德1949年的工作,並在以後為許多學者所發展。線性統計模型中參數的最小二乘估計的強相合性研究始於20世紀60年代,-取得很大的進展。
(2)最優漸近正態估計
簡稱BAN估計。設X1、X2…Xn為從一總體中隨機獨立地抽出的樣本,總體分布具有密度函式或機率函式 ƒ(x,θ),滿足一定的正則條件,設g(θ)為待估函式,記 式中稱為費希爾信息量,若g(θ)的估計量為抭n(X1、X2…Xn),當n→時,依分布收斂於常態分配 N(0,v2(θ)),就稱此估計量為g(θ)的 BAN估計。在g(θ)的一類漸近正態估計中,以這種估計的漸近方差最小,故稱為最優漸近正態估計。在一般條件下,最大似然估計是BAN估計。
(3)漸近有效估計
