
高斯過程回歸(Gaussian Process Regression, GPR)是使用高斯過程(Gaussian Process, GP)先驗對數據進行回歸分析的非參數模型(non-parameteric model)。
GPR的模型假設包括噪聲(回歸殘差)和高斯過程先驗兩部分,其求解按貝葉斯推斷(Bayesian inference)進行。若不限制核函式的形式,GPR在理論上是緊緻空間(compact space)內任意連續函式的通用近似(universal approximator)。此外,GPR可提供預測結果的後驗,且在似然為常態分配時,該後驗具有解析形式。因此,GPR是一個具有泛用性和可解析性的機率模型。
基於高斯過程及其核函式所具有的便利性質,GPR在時間序列分析、圖像處理和自動控制等領域的問題中有得到套用。GPR是計算開銷較大的算法,通常被用於低維和小樣本的回歸問題,但也有適用於大樣本和高維情形的擴展算法。
基本介紹
- 中文名:高斯過程回歸
- 外文名:Gaussian Process Regression, GPR
- 類型:機器學習算法,非參數算法
- 提出者:Carl E. Rasmussen,Christopher K.I. Williams
- 提出時間:1996年
- 學科:統計學,人工智慧
- 套用:時間序列分析,圖像處理,自動控制
歷史,理論,模型推導,核函式,算法,正態似然,非正態似然,擴展算法,有關概念,性質,套用,
歷史
與GPR有關的早期研究大致可分為3部分,在時間序列分析中,安德雷·柯爾莫哥洛夫(Андрей Николаевич Колмогоров)和羅伯特·維納(Robert Wiener)在二十世紀40年代提出了估計0均值平穩高斯過程信號的濾波技術。隨後出現的卡爾曼濾波(Kalman filter)提供了估計高斯隱變數(latent variable)的有效方法。在地統計學領域,1963年提出的克里金法(Kriging)首次實現了平穩隨機場的非參數回歸,其後在二十世紀90年代出現的貝葉斯克里金提供了與GPR接近或等價的高斯隨機場估計。在機器學習方面,包含無限節點的貝葉斯神經網路(Bayesian neural network)和各類核學習(kernel learning)方法例如核嶺回歸(kernel ridge regression)為GPR的核函式超參數求解帶來了啟發。
GPR作為機器學習一般方法的提出來自劍橋大學(University of Cambridge)學者Carl E. Rasmussen和愛丁堡大學(University of Edinburgh)學者Christopher K. I. Williams,二者在1996年發表的研究按函式空間觀點給出了GPR的求解系統並討論了GPR超參數的極大似然估計和蒙特卡羅方法求解。
理論
模型推導
這裡給出GPR在權重空間(weight-space)觀點和函式空間(function-space)觀點下的模型推導,前者由貝葉斯線性回歸(Bayesian linear regression)出發,通過特徵空間的映射得到GPR的預測形式,後者由高斯過程出發,以更簡潔的方式得到與前者等價的結果。
權重空間觀點
參見:貝葉斯線性回歸


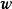

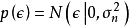


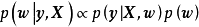

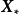
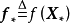

貝葉斯線性回歸是一個線性參數模型,為使其表示樣本間的非線性關係,可以使用給定的函式將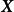 映射至高維空間:
映射至高維空間:

由於映射函式 是固定的,即與模型權重無關,因此可直接帶入貝葉斯線性回歸的結果得到:
是固定的,即與模型權重無關,因此可直接帶入貝葉斯線性回歸的結果得到:



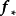

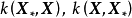
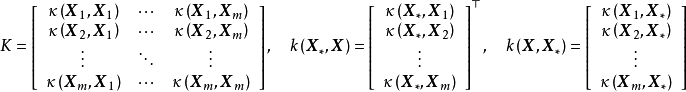
函式空間觀點
參見:高斯過程
對回歸模型 ,若函式
,若函式 的形式不是固定的,則其為潛函式(latent function)。潛函式的每個取值都是函式空間(function-space)的一個測度。GPR取該函式空間的先驗為高斯過程(Gaussian Process, GP),不失一般性,這裡表示為0均值高斯過程:
的形式不是固定的,則其為潛函式(latent function)。潛函式的每個取值都是函式空間(function-space)的一個測度。GPR取該函式空間的先驗為高斯過程(Gaussian Process, GP),不失一般性,這裡表示為0均值高斯過程:
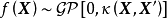
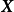
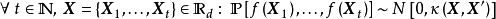

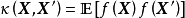
給定N組學習樣本 ,作為對算法的推導,假設回歸殘差服從iid常態分配:
,作為對算法的推導,假設回歸殘差服從iid常態分配: ,則GPR在高斯過程先驗和常態分配似然下求解回歸模型的後驗:
,則GPR在高斯過程先驗和常態分配似然下求解回歸模型的後驗: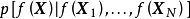 ,並對測試樣本的測試結果進行估計(非正態似然的情形參見算法部分)。具體地,由回歸模型和高斯過程的定義,
,並對測試樣本的測試結果進行估計(非正態似然的情形參見算法部分)。具體地,由回歸模型和高斯過程的定義, 和
和 的機率分布為:
的機率分布為:

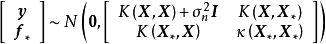

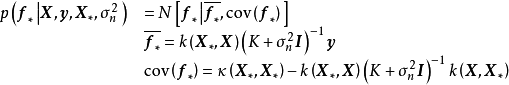
和正態似然求解的後驗(右)") 一維高斯過程先驗(左)和正態似然求解的後驗(右)
一維高斯過程先驗(左)和正態似然求解的後驗(右)由上述預測形式的推導可知,GPR在假設0均值高斯過程先驗時,解得的後驗往往不是0均值的,因此0均值先驗具有泛用性。但作為說明,GPR也可使用均值不為0的高斯過程先驗,此時常見的做法是將潛函式表示為一組顯式基函式(explicit basis function):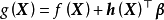 。在給定基函式的常態分配先驗
。在給定基函式的常態分配先驗 時,
時, 是具有如下形式的高斯過程:
是具有如下形式的高斯過程:

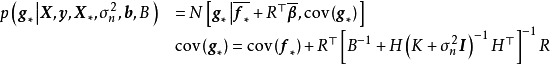


核函式
參見:核函式
GPR使用高斯過程作為先驗,即假設了學習樣本是高斯過程的採樣,因此其估計結果與核函式有密切聯繫。GPR中核函式的實際意義為協方差函式(covariance function),描述了學習樣本間的相關性,因此其不是通過核方法簡化計算的手段,而是模型假設的一部分。這裡對GPR常見的核函式進行簡單介紹,並引入核函式計算的加速方法。和對應的高斯過程採樣(下)") RBF核、周期核、線性核(上)和對應的高斯過程採樣(下)
RBF核、周期核、線性核(上)和對應的高斯過程採樣(下)
RBF核、周期核、線性核(上)和對應的高斯過程採樣(下)核函式的選擇
若GPR的先驗為平移不變(transformation invariant)的平穩高斯過程時,可用的核函式包括徑向基函式核(RBF kernel)、馬頓核(Matérn kernel)、指數函式核(exponential kernel)、二次有理函式核(rational quadratic kernel, RQ kernel)等,以RBF核為例,其解析形式如下:
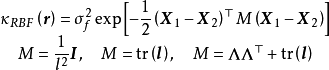
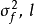
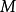

GPR也可使用非平穩高斯過程,此時常見的核函式選擇為周期核(periodic kernel)與多項式函式核(polynominal kernel),二者分別賦予高斯過程周期性和旋轉不變性(rotation invariant)。
核矩陣求逆的計算簡化
由模型推導部分可知,GPR要求計算核矩陣的逆矩陣: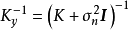 ,若使用Cholesky分解(Cholesky decomposition)求逆,則對N組學習樣本,其計算複雜度為
,若使用Cholesky分解(Cholesky decomposition)求逆,則對N組學習樣本,其計算複雜度為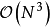 。因此隨著學習樣本的增加,GPR的計算開銷會顯著增大。這裡簡單介紹核矩陣求逆的簡化方法以應對上述問題,一般地,這些方法除GPR外也適用於其它核學習(kernel learning)方法,例如核嶺回歸、支持向量機(Support Vector Machine, SVM)等。
。因此隨著學習樣本的增加,GPR的計算開銷會顯著增大。這裡簡單介紹核矩陣求逆的簡化方法以應對上述問題,一般地,這些方法除GPR外也適用於其它核學習(kernel learning)方法,例如核嶺回歸、支持向量機(Support Vector Machine, SVM)等。
1. 選取數據子集(subset of datapoints, SD)
由於GPR可以在少量學習樣本的情形下給出回歸問題的可靠估計,因此從學習樣本中合理選擇一個子集可以顯著降低核矩陣的大小,但不對GPR的表現造成顯著影響。選取SD的常見方法是通過尋找微分熵(differential entropy)最大的學習樣本作為支持向量定義SD,選取過程的計算複雜度為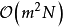 ,在選取較小子集的情形下簡化了計算,使用SD最佳化的高斯過程建模被稱為稀疏高斯過程(sparse Gaussian process),或信息向量機(Informativevector machine, IVM)。
,在選取較小子集的情形下簡化了計算,使用SD最佳化的高斯過程建模被稱為稀疏高斯過程(sparse Gaussian process),或信息向量機(Informativevector machine, IVM)。
2. 低秩近似(low-rank approximation)
低秩近似將核矩陣近似為一系列低秩矩陣的乘積以簡化求逆計算,具體地,N×N的核矩陣可以近似表示為: ,其中
,其中 的大小分別為N×m、m×m、m×N,此時由Sherman-Morrison-Woodbury定理可得:
的大小分別為N×m、m×m、m×N,此時由Sherman-Morrison-Woodbury定理可得:


確定低秩矩陣的常見方法包括Nyström法(Nyström method)、子集回歸法(subset ofregressors, SR)、映射過程近似(projected process approximation, PP)、BCM(Bayesian committee machine)等,這裡對前兩者進行介紹。Nyström法將核矩陣分解為4個分塊矩陣並在構建低秩近似後直接帶入GPR的預測形式: SR按與Nyström法相同的方式構建分塊矩陣,但其首先將GPR的預測形式改寫為核矩陣子集的回歸併帶入低秩矩陣,例如對GPR的均值部分有:
SR按與Nyström法相同的方式構建分塊矩陣,但其首先將GPR的預測形式改寫為核矩陣子集的回歸併帶入低秩矩陣,例如對GPR的均值部分有: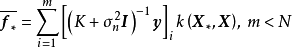 。
。
算法
正態似然
GPR的求解也被稱為超參學習(hyper-parameter learning),是按貝葉斯方法通過學習樣本確定核函式中超參數的過程。由貝葉斯定理(Bayes' theorem)可知,GPR的超參數後驗有如下表示:
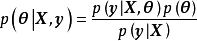

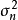


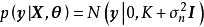
極大似然估計(Maximum Likelihood Estimation, MLE)
MLE通過令GPR的似然取極大值實現對超參數的單點估計。不失一般性,對0均值先驗的GPR,帶入聯合常態分配的解析形式並求其負自然對數可得:


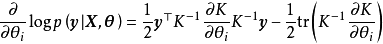
GPR的對數似然不是凸函式,且其最佳化複雜度隨學習樣本的增加而增大,在大量學習樣本的情形下,可能會發現多個局部最優,且局部最優解的差異很大的情形,考慮解出的核函式超參數通常表示高斯過程的特徵長度尺度,多個局部最優意味著學習樣本可以按多個尺度進行回歸,其中小尺度的模型複雜度高但考慮更多局部特徵,大尺度的模型反之。和得到的後驗(下)") 包含2個局部最優解的GPR對數似然(上)和得到的後驗(下)
包含2個局部最優解的GPR對數似然(上)和得到的後驗(下)
包含2個局部最優解的GPR對數似然(上)和得到的後驗(下)除MLE外,GPR也可通過極大後驗估計(Maximum A Posteriori estimation, MAP)求解。MAP是與MLE相近的估計方法,其最佳化目標是似然和先驗的乘積。因為MAP與MLE在正態後驗時得到的結果等價,在其他情形下的結果也相近,卻引入了先驗和額外的計算,因此在GPR研究中被較少提及。
極大偽似然估計(maximum pseudo-likelihood estimator, MPLE)
使用MPLE求解GPR的過程也被稱為交叉驗證(cross-validation),相比於MLE,其改變是對學習樣本使用留一法(Leave One Out, LOO)計算其偽似然(pseudo-likelihood)的負自然對數:

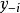

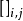

編程實現
這裡提供一個使用GPy封裝的GPR模型的例子:
# 導入模組import GPy # conda install -c conda-forge GPy import numpy as np# 生成學習樣本N=100; sigma_n=0.2X = np.random.uniform(-2*np.pi, 2*np.pi,(N, 1))y = np.sin(X)+np.random.randn(N, 1)*sigma_n# 初始化RBF核: variance=1, lengthscale=1, variance of noise=0.1k_RBF = GPy.kern.RBF(1, 1, 0.1) # 建立GPR模型model = GPy.models.GPRegression(X, y, kernel=k_RBF)model.plot() # 繪製高斯過程先驗model.optimize(messages=True) # 求解GPR超參數: MLE + 擬牛頓法(BFGS)model.plot(); # 繪製高斯過程後驗# 單點預測mean, var = model.predict(np.array([[3*np.pi]]))print('Predicted mean and var at X=3pi: {}, {}'.format(mean, var))非正態似然
在似然不服從常態分配,例如處理異方差噪聲數據時,GPR對測試數據的後驗沒有解析形式,此時可以使用的解析近似(analytical approximation)方法,例如拉普拉斯近似(Laplace Approximation, LA)和期望傳播(Expectation Propagation, EP)將非正態後驗近似表示為正態後驗。LA和EP的推導可參見Rasmussen and Williams (2006), pp.41-60。
數值方法可用在非正態似然,或核函式超參數過多,不利於MLE問題最佳化的情形下求解GPR。選擇包括蒙特卡羅方法(Monte Carlo)和變分貝葉斯估計(Variational Bayesian Inference, VBI)。VBI使用Jensen不等式得到GPR對數似然的凸函式下界作為代理損失並使用梯度算法求解,其優勢是計算複雜度接近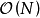 ,顯著簡化了計算。蒙特卡羅方法被認為是在GPR數值解法中擁有高準確度和泛用性的方法,其原理是使用大量計算開銷疊代生成隨機數逼近GPR後驗。蒙特卡羅求解GPR的常見方法為混合蒙特卡羅(Hybrid Monte Carlo, HMC),其步驟接近於Metropolis-Hastings算法,但通過“動量”項限制了隨機遊走的取值。HMC求解GPR的例子可參見Rasmussen (1996)。
,顯著簡化了計算。蒙特卡羅方法被認為是在GPR數值解法中擁有高準確度和泛用性的方法,其原理是使用大量計算開銷疊代生成隨機數逼近GPR後驗。蒙特卡羅求解GPR的常見方法為混合蒙特卡羅(Hybrid Monte Carlo, HMC),其步驟接近於Metropolis-Hastings算法,但通過“動量”項限制了隨機遊走的取值。HMC求解GPR的例子可參見Rasmussen (1996)。
擴展算法
這裡給出與高斯過程回歸有關的擴展算法,但更一般地,這些方法是高斯過程模型的擴展,除回歸問題外也可被套用於其它機器學習主題。
封裝高斯過程(Warped Gaussian Process, WGP)
WGP通過對GPR進行非線性變換將其拓展至非高斯過程的情形,具體地,WGP首先在特徵空間選擇一個單調封裝函式(monotonic warping function),將學習樣本變換至封裝函式指定的潛空間後再求解包含封裝函式超參數的極大似然。WGP的中封裝函式的選擇通常為雙曲正切函式(hyperbolic tangent)線性組合,這裡給出WGP對應於GPR的模型和算法:
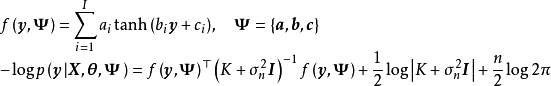

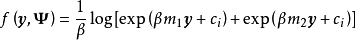
半參數高斯過程(Semi-parametric Gaussian Processes, SGP)
SGP是在回歸問題中將高斯過程模型與參數模型線性組合以獲得兩者優點——GPR的靈活性和參數模型在高維問題中利用數據的有效性——的算法。具體地,SGPR構建了如下求解系統:

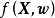
深度高斯過程(deep Gaussian Process, DGP)
由性質可知,高斯過程可以視為一個擁有單隱含層和無限個隱含層節點的多層感知器(Multi-Layer Perceptron, MLP),DGP是MLP由單隱含層推廣至多隱含層時得到的高斯過程,即擁有多個隱含層和無限寬度的MLP。按定義,DGP是一組從高斯過程先驗中選擇的函式的分布:
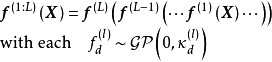


 由兩種等價觀點給出的DGP
由兩種等價觀點給出的DGP可加高斯過程(Additive Gaussian Process, AGP)
GPR的常見核函式,例如RBF核、馬頓核等,被認為在高維特徵空間的學習問題中泛化能力較差,而AGP即是為解決GPR高維學習問題而提出的擴展方法。AGP利用核函式性質,在構建高斯過程先驗時對核函式進行了組合和結構最佳化。介紹性地,AGP在不同維度將不同結構的核函式相加作為先驗,並通過貝葉斯階層核學習(Bayesian Hierarchical Kernel Learning, HKL)更新超參數以去除對學習樣本解釋不利的結構。以RBF核為例,其1階可加高斯過程先驗可表示為:


有關概念
高斯過程分類(Gaussian Process Classification, GPC)
GPC是使用高斯過程作為先驗的分類器,在二元分類中,GPC在對潛函式進行估計後將其作為Sigmoid函式的輸入得到分類機率;在多元分類中,則將Sigmoid函式替換為歸一化指數函式。以二元分類為例,因為標籤數據是 取值的二項分布隨機變數,所以對應的GPC似然是潛函式對學習樣本的因子乘積:
取值的二項分布隨機變數,所以對應的GPC似然是潛函式對學習樣本的因子乘積:
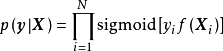
克里金法(Kriging)
主詞條:克里金法
克里金法是與GPR相近的非參數模型,常見於隨機場的插值問題。若協方差函式的形式等價,簡單克里金(simple Kriging)和普通克里金(ordinary Kriging)的輸出與GPR在正態似然下輸出的數學期望相同,若克里金法使用高斯隨機場假設,則給出的置信區間也與GPR相同。克里金法與GPR的不同點在於,前者假設隨機場為固有平穩過程(intrinsically stationary process)並給出其對測試樣本的最優無偏估計(Best Linear Unbiased Prediction, BLUP);後者假設隨機場為高斯過程並給出其對測試樣本的完整後驗。此外,考慮在地統計學中套用的常見情形,克里金法通常不加入噪聲,其估計結果在學習樣本處與學習目標完全相同。
有一些克里金法的擴展方法與GPR等價,例如Handcock and Stein (1993)和Handcock and Wallis (1994)提出的包含貝葉斯推斷的克里金法使用了各向同性的馬頓核高斯過程先驗,並在正態似然假設下按MLE求解超參數。
性質
在使用特定核函式時,GPR是一個通用近似(universal approximator),具體地,若實數域內有緊緻空間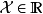 和賦范向量空間(normed vector space)
和賦范向量空間(normed vector space) ,則可以證明,對任意函式
,則可以證明,對任意函式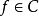 ,等價核(Equivalent Kernel, EK)構成的再生核希爾伯特空間(Reproducing Kernel Hilbert Space, RKHS)內總是存在
,等價核(Equivalent Kernel, EK)構成的再生核希爾伯特空間(Reproducing Kernel Hilbert Space, RKHS)內總是存在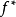 能夠按任意精度逼近原函式,即RKHS內總是存線上性組合:
能夠按任意精度逼近原函式,即RKHS內總是存線上性組合: 。等價核的例子包括RBF核、二次有理函式核、指數函式核等。
。等價核的例子包括RBF核、二次有理函式核、指數函式核等。
作為非參數高斯過程模型的性質:GPR的複雜程度取決於學習樣本,因此天然避免了過擬合(overfitting)問題。當測試樣本與學習樣本在特徵空間的距離趨於無窮時,GPR的估計結果趨於其高斯過程先驗,例如對0均值的各向同性高斯過程先驗有: 。由於高斯過程可以通過協方差函式模擬隨機變數間的相關性,因此GPR可套用於平移不變、旋轉不變或周期性數據的回歸問題,但同時,由於核函式/非參數方法的局限,GPR在高維數據的學習中表現不佳,該現象有時被稱為“維數詛咒(curse of dimensionality)”。此外由理論部分可知,GPR的計算複雜度較高。一些研究給出了計算量更低的改進算法並取得了效果,但總體而言,GPR是一個為小樣本設計的機器學習算法。
。由於高斯過程可以通過協方差函式模擬隨機變數間的相關性,因此GPR可套用於平移不變、旋轉不變或周期性數據的回歸問題,但同時,由於核函式/非參數方法的局限,GPR在高維數據的學習中表現不佳,該現象有時被稱為“維數詛咒(curse of dimensionality)”。此外由理論部分可知,GPR的計算複雜度較高。一些研究給出了計算量更低的改進算法並取得了效果,但總體而言,GPR是一個為小樣本設計的機器學習算法。
作為貝葉斯方法的性質:GPR是一個包含全貝葉斯特性(full Bayesian)的回歸模型,可以給出測試數據的完整後驗。此外,在似然為常態分配時,GPR給出的後驗是具有閉合形式的聯合常態分配,即GPR具有可解析性,該性質在非參數模型中並不多見。
與核學習方法的比較:GPR與適用於回歸問題的核學習(kernel learning)方法,例如核嶺回歸、支持向量回歸(support vector regression)等都使用了核函式與核方法,且可以通過相同的方式簡化核矩陣求逆計算,但對後者,其核函式是輸入空間向高維特徵空間的映射,而GPR中的核函式是高斯過程協方差函式的模型,表示隨機變數間的相關性。上述不同在求解中的體現是,GPR的“學習”是通過數據確定核函式超參數的過程,而核方法的“學習”,是在給定核函式超參數後求解模型權重或尋找支持向量的過程。
與人工神經網路(Artificial Neural Network, ANN)的關係:ANN是參數模型,在理論和結構上與GPR有較大差異,但二者在套用中有重疊,例子包括時間序列分析和計算機視覺問題。若學習樣本充足,ANN由於使用隨機梯度下降方法進行學習,在求解效率上優勢明顯;但在要求給出機率輸出時,GPR是更合適的方法。ANN中的多層感知器(Multi-Layer Perceptron, MLP)與高斯過程存在聯繫,高斯過程可以由擁有單隱含層和無限個隱含層節點的MLP導出。具體地,對如下預測形式的MLP: 若其權重為iid隨機變數且均值為0,方差為有限值,則由中心極限定理(central limit theorem)可推出,當隱含層節點數n趨於無窮時,模型輸出的聯合分布趨於0均值的聯合常態分配:
若其權重為iid隨機變數且均值為0,方差為有限值,則由中心極限定理(central limit theorem)可推出,當隱含層節點數n趨於無窮時,模型輸出的聯合分布趨於0均值的聯合常態分配: 該結論不要求iid權重服從常態分配,但當權重服從iid常態分配時,有限個隱含層節點的MLP也可表示為高斯過程。另一方面,MLP也可以由高斯過程導出,由Mercer定理可知,核函式可以表示為映射函式的內積:
該結論不要求iid權重服從常態分配,但當權重服從iid常態分配時,有限個隱含層節點的MLP也可表示為高斯過程。另一方面,MLP也可以由高斯過程導出,由Mercer定理可知,核函式可以表示為映射函式的內積: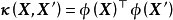 ,因此可視為以
,因此可視為以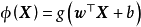 為隱含層特徵(輸出)的MLP。
為隱含層特徵(輸出)的MLP。
套用
GPR在各類低維的回歸問題中均可套用,尤其是時間序列數據的預測,例子包括太陽輻射的有關變數、風速、土壤溫度、冒納羅亞觀測站(Mauna Loa Observatory,MLO)的全球對流層平均二氧化碳濃度等。在圖像處理(image processing)方面,GPR被用於圖像去噪和生成超解析度圖像。在自動控制方面,GPR被用於機械臂(robotic arm)數據的實時學習,也有研究開發了GPR的機器人學習(robot learning)系統。
包含GPR的編程模組
基於Python開發的機器學習模組scikit-learn提供封裝的GPR工具GaussianProcessRegressor,其求解方法為BFGS算法(Broyden-Fletcher-Goldfarb-Shanno)的MLE,擁有自定義的求解器函式接口。在核函式方面,scikit-learn包含RBF核、馬頓核、二次有理核、指數-周期核、多項式核以及自定義核函式的API工具。
由謝菲爾德機器學習團隊(Sheffield machine learning group)開發的Python高斯過程建模工具GPy提供了GPR的完整求解系統和核函式,包括異方差噪聲GPR、隱變數模型,解析近似、VBI和蒙特卡羅求解、稀疏高斯過程和低秩近似。此外有基於GPy的模型超參數最佳化工具GPyOpt可用。
pyGPs是基於Python開發的面向對象高斯過程建模套用,包含可視化學習界面,在功能上包括了常見核函式、稀疏高斯過程和解析近似。
