
基本介紹
- 中文名:自適應邊緣提取
- 外文名:Adaptive edge extraction
- 邊緣提取方法:直接在空間域中或在變換域中提取
- 邊緣:圖像最基本的特徵之一
- 優點:具備較好的檢測效果
- 套用學科:計算機科學、生物醫學、通信工程
簡介,定義,發展歷史,自適應Canny邊緣提取算法,平滑圖像,改進梯度的幅值和方向,非極大值抑制,基於梯度信息方法來求雙閾值,快速自適應邊緣提取方法,對整幅圖抽樣降低解析度,抽樣圖中自適應檢測邊緣,整幅圖中目標輪廓精確定位,
簡介
定義
邊緣是圖像最基本的特徵之一,邊緣檢測的效果將直接影響到圖像的分析、識別和理解。因此,邊緣檢測已經成為圖像處理領域中十分重要的環節,有著廣泛的套用。圖像的邊緣提取是圖像處理的傳統課題,目前已經有許多邊緣提取方法。總的來說,邊緣提取有兩種操作方式:一是直接在空間域中進行提取,如Sobel,Roberts等運算元,它們在邊緣的定位和檢測精度上效果較好,但是對噪聲敏感;另一種方式是先對圖像做一變換,在其變換域中提取邊緣。自適應邊緣提取就是在處理和分析過程圖像邊緣中,根據處理數據的數據特徵自動調整處理方法、處理順序、處理參數、邊界條件或約束條件,使其與所處理數據的統計分布特徵、結構特徵相適應,以取得最佳的提取效果。
發展歷史
傳統的邊緣檢測算法包括Roberts運算元、Prewitt運算元、Sobel運算元等一階微分運算元,以及Laplacian運算元、LOG運算元等二階微分運算元。通常,這類運算元以一階導數極大值點或二階導數過零點作為候選邊緣點,通過選取合適的閾值,從中提取圖像邊緣,具有簡單、易於實現、運算速度快等特點。但是,由於微分運算對噪聲往往比較敏感,抗干擾性能差,邊緣不夠精細,因此在實際套用中受到了限制。
為了進一步提高邊緣檢測算法的性能,Canny於1986年提出了邊緣檢測運算元應滿足的最優準則:信噪比準則、定位精度準則和單邊緣回響準則,並由此推導出了Canny最佳邊緣檢測算法。該算法具備較好的檢測效果,迄今為止,依然是主要的邊緣檢測方法。
然而,利用Canny進行檢測邊緣時,高、低閾值和高斯濾波參數都需要人為確定,而且不同的參數對於邊緣檢測的結果影響很大,實際圖像易受光照不均和噪聲等干擾,使圖像中存在噪聲以及模糊的邊緣。在這種情況下,如果簡單地使用傳統Canny運算元進行邊緣檢測,一方面很難設定閾值和高斯濾波方差參數;另一方面若對整幅圖像採用單一閾值,會檢測出假邊緣,同時還會丟失一些灰度變化緩慢的局部邊緣。為此,國內外很多學者對高斯濾波參數和閾值的建立進行了研究,提出了一些自適應方法。但是,這些方法也需要人為地設定閾值比例係數,無法排除人為因素的干擾。
自適應Canny邊緣提取算法
近幾年來,已有不少文章對Canny算法進行改進,現提出新的方法是根據σ大小來自適應確定高低閾值,從而達到改進Canny自適應邊緣提取算法,並取得了良好的效果。
平滑圖像
用一維高斯函式對原始圖像f(x,y)進行列和行平滑,得到平滑圖像I(x,y):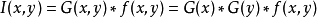
其中*是卷積符號,平滑濾波可以達到抑制噪音的作用,消除噪聲空間尺度小於高斯係數σ。
改進梯度的幅值和方向
用一階偏導數的有限差分計算梯度的幅值和方向。對圖像的每個像素點I(x,y),採用3×3模板來作為對x和y方向一階偏導數Px(x,y)和Py(x,y)近似計算梯度的大小和方向。考慮到當前點在不同方向上對其影響梯度的大小,採用3×3模板增強圖像的平滑和抑制噪聲的作用



θ(i,j)=Py(i,j)/Px(i,j)
非極大值抑制
通過抑制梯度線上所有非屋脊帶峰值的幅值來細化邊緣強度中的梯度幅值屋脊,如果圖像f(x,y)上像素點(i,j)的邊緣強度M(i,j)小於沿著梯度線方向上的兩個相鄰像素點的邊緣強度,則認為該像素點為非邊緣點,將M(i,j)置為零。
基於梯度信息方法來求雙閾值
套用灰度變化的梯度信息描述圖像的紋理特徵和邊緣特徵,通過梯度信息熵和標準差方法來分析圖像紋理粗細,進而判斷圖像的分布情況,來確定比較合適的高低閾值。根據圖像的紋理信息來分析梯度的特徵,通過圖像中的梯度信息熵及其標準差作為圖像在不同方向上的影響因子來確定閾值,能夠達到自適應地確定高低雙閾值。
把圖像經過非極大值抑制後的非邊緣像素點歸為集合N,並且把集合N的256灰度級映射成64灰度級,這樣能節省運行時間的開銷。集合N中任一元素(i,j)在圖像中沿著(0°,45°,90°,135°)相隔距離為d(d=1,2,3)的像素點之間平均差分,構成了圖像的空間分布矩陣P[i,j,θ]。P[i,j,θ]表示圖像上的像素點(i,j)在沿著一定方向θ,相距為均值d的歸一化機率分布。定義各個方向上的熵,其表示如下。

式中m和n分別為圖像的高度和寬度,P(i,j,θ)表示在空間分布中的像素點(i,j)在θ方向上的機率。
在電腦程式中用E(θ)和D(θ)表示圖像在各個方向上熵的期望和熵的標準差,通過大量的圖像數據實驗,利用熵和標準差來得到動態高低熵值(th2和th1),達到了自適應的要求,關係表達式如下


由於在集合N中存在大量的非邊緣像素點,對應P[i,j,θ]中將會出現大量零點、較小數值點和少量的較大數值點。對於灰度分布陡峭的圖像,P[i,j,θ]中出現分布較多的較大數值點,相應的H(θ)變大。如果圖像的邊緣越尖銳,圖像的熵值較大;反之,如果圖像的邊緣越緩和,圖像的熵值較小。熵標準差是從整體上反映圖像熵在各個方向上的分布情況,通過標準差的分析來控制偽邊緣的影響係數。如果熵在四個方向上都有明顯的變化,熵標準差的值比較小,偽邊緣的可能性就較大,影響係數較大;如果熵在某個方向上都有明顯的變化,熵標準差的值比較大,偽邊緣的可能性就較小,影響係數較小。所以說公式能合理地確定高低閾值,能構動態確定閾值,達到自適應效果。 自適應Canny 算法邊緣圖像
自適應Canny 算法邊緣圖像
自適應Canny 算法邊緣圖像快速自適應邊緣提取方法
快速自適應提取邊緣的方法是對整幅圖進行一次抽樣,降低圖像解析度以縮小搜尋範圍,在抽樣圖上進行邊緣檢測,並以此為指導在整幅圖上局部精確定位邊緣點,算法簡單,運算量小。在檢測邊緣點時利用Canny算法中非局部極大值抑制和雙閾值邊緣連線理論,並通過對圖像梯度直方圖的統計自適應地選取閾值。該方法算法簡單,自動化程度高,耗時少,能較滿意地檢測出目標的輪廓,抑制細小邊緣。
對整幅圖抽樣降低解析度
對整幅圖抽樣得到低解析度的抽樣圖是為解決整幅圖的遍歷搜尋帶來的大計算量問題。採用間隔抽樣和邏輯運算相結合的方法,以達到減少運算量和避免邊緣丟失的雙重目的。採用5×5個像素組成的視窗抽樣為一個像素,抽樣後的圖將減少為原始圖像的二十五分之一,為避免抽樣過程中邊緣的丟失,在5×5的視窗中選擇幾個有代表性質的像素點進行邏輯運算。具體做法如下。 抽樣示意圖
抽樣示意圖
抽樣示意圖整幅圖上的每5×5個像素點在抽樣圖上用一個像素點來表示,如圖所示,用圖中標示出來的4個黑點元素的均值代替抽樣圖上對應的一個像素點。原始圖中選取的這4個像素點與5×5視窗中的其餘每個像素點均相鄰接,它們4個的灰度均值能很好地代表這個區域的紋理或邊緣信息。
抽樣圖中自適應檢測邊緣
基於圖像邊緣灰度突變的特性,可以利用像素點梯度值來區分邊緣點和非邊緣點,其中梯度值的閾值選取很重要,它是提取出真實邊緣點的關鍵。通過對實驗圖像的梯度直方圖觀察得知,梯度直方圖幾乎服從統一分布,可描述為圖所示。 梯度閾值
梯度閾值
梯度閾值其中,x軸代表梯度值,y軸代表梯度的數。a為梯度直方圖的均值,b-a為梯度直方圖的方差。
梯度值較低的主體高峰部分對應圖像中的非邊緣區域,而梯度值較高的平緩尾部對應邊緣區域。在機率論中,梯度均值是一個描述主體梯度值集中位置的統計特徵,標準差則是一個將主體高峰部分與平緩尾部部分分開的統計特徵。在梯度直方圖這類分布函式中,統計量b能適當到將邊緣區域和非邊緣區域分開。
因此利用梯度直方圖的統計特性,選擇b值作為梯度閾值能在滿足全局最優的原則下自適應地檢測出邊緣,自動化程度高。
整幅圖中目標輪廓精確定位
在抽樣圖中檢測到的邊緣反映了目標輪廓在整幅圖中的大致位置,以抽樣圖中邊緣位置信息為指導,在整幅圖中相應的局部範圍內搜尋邊緣點就可得到目標輪廓的精確位置,且很大程度上減少了計算量,其流程圖如圖所示。 邊緣映射示意圖
邊緣映射示意圖
邊緣映射示意圖在對整幅圖抽樣時,是以整幅圖中每5×5個像素點抽樣為1個像素點的,因此在抽樣圖中檢測到的每一個邊緣點在向整幅圖映射時最小的映射範圍為5×5的區域,為了檢測到完整連續的目標輪廓可適當擴大映射範圍。
對於抽樣圖中的一個邊緣點(x,y),將其坐標擴大到原來的5倍後變為(5x,5y),在原始圖像中以(5x,5y)為中心點開一個大小為6×6的視窗,將其中的像素點標記出來,即完成抽樣圖中的一個邊緣點向原始圖像中的映射。對抽樣圖中的每個邊緣點都進行同樣的映射處理便可得到邊緣的搜尋範圍。
