
AlexNet是2012年ImageNet競賽冠軍獲得者Hinton和他的學生Alex Krizhevsky設計的。也是在那年之後,更多的更深的神經網路被提出,比如優秀的vgg,GoogLeNet。 這對於傳統的機器學習分類算法而言,已經相當的出色。
基本介紹
- 外文名:AlexNet
- 類型:神經網路
- 提出時間:2012
- 提出者:Hinton及其學生
模型簡介,AlexNet特點,使用了Relu激活函式,標準化,Dropout,AlexNet的TensorFlow實現,
模型簡介
AlexNet中包含了幾個比較新的技術點,也首次在CNN中成功套用了ReLU、Dropout和LRN等Trick。同時AlexNet也使用了GPU進行運算加速。
AlexNet將LeNet的思想發揚光大,把CNN的基本原理套用到了很深很寬的網路中。AlexNet主要使用到的新技術點如下:
(1)成功使用ReLU作為CNN的激活函式,並驗證其效果在較深的網路超過了Sigmoid,成功解決了Sigmoid在網路較深時的梯度彌散問題。雖然ReLU激活函式在很久之前就被提出了,但是直到AlexNet的出現才將其發揚光大。
(2)訓練時使用Dropout隨機忽略一部分神經元,以避免模型過擬合。Dropout雖有單獨的論文論述,但是AlexNet將其實用化,通過實踐證實了它的效果。在AlexNet中主要是最後幾個全連線層使用了Dropout。
(3)在CNN中使用重疊的最大池化。此前CNN中普遍使用平均池化,AlexNet全部使用最大池化,避免平均池化的模糊化效果。並且AlexNet中提出讓步長比池化核的尺寸小,這樣池化層的輸出之間會有重疊和覆蓋,提升了特徵的豐富性。
(4)提出了LRN層,對局部神經元的活動創建競爭機制,使得其中回響比較大的值變得相對更大,並抑制其他反饋較小的神經元,增強了模型的泛化能力。
(5)使用CUDA加速深度卷積網路的訓練,利用GPU強大的並行計算能力,處理神經網路訓練時大量的矩陣運算。AlexNet使用了兩塊GTX 580 GPU進行訓練,單個GTX 580隻有3GB顯存,這限制了可訓練的網路的最大規模。因此作者將AlexNet分布在兩個GPU上,在每個GPU的顯存中儲存一半的神經元的參數。因為GPU之間通信方便,可以互相訪問顯存,而不需要通過主機記憶體,所以同時使用多塊GPU也是非常高效的。同時,AlexNet的設計讓GPU之間的通信只在網路的某些層進行,控制了通信的性能損耗。
(6)數據增強,隨機地從256*256的原始圖像中截取224*224大小的區域(以及水平翻轉的鏡像),相當於增加了2*(256-224)^2=2048倍的數據量。如果沒有數據增強,僅靠原始的數據量,參數眾多的CNN會陷入過擬合中,使用了數據增強後可以大大減輕過擬合,提升泛化能力。進行預測時,則是取圖片的四個角加中間共5個位置,並進行左右翻轉,一共獲得10張圖片,對他們進行預測並對10次結果求均值。同時,AlexNet論文中提到了會對圖像的RGB數據進行PCA處理,並對主成分做一個標準差為0.1的高斯擾動,增加一些噪聲,這個Trick可以讓錯誤率再下降1%。
AlexNet特點
使用了Relu激活函式
Relu函式: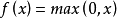
 圖四
圖四基於ReLU的深度卷積網路比基於tanh和sigmoid的網路訓練快數倍。
標準化
使用ReLU 後,會發現激活函式之後的值沒有了tanh、sigmoid函式那樣有一個值域區間,所以一般在ReLU之後會做一個normalization,LRU就是穩重提出一種方法,在神經科學中有個概念叫“Lateral inhibition”,講的是活躍的神經元對它周邊神經元的影響。
Dropout
Dropout也是經常說的一個概念,能夠比較有效地防止神經網路的過擬合。 相對於一般如線性模型使用正則的方法來防止模型過擬合,而在神經網路中Dropout通過修改神經網路本身結構來實現。對於某一層神經元,通過定義的機率來隨機刪除一些神經元,同時保持輸入層與輸出層神經元的個人不變,然後按照神經網路的學習方法進行參數更新,下一次疊代中,重新隨機刪除一些神經元,直至訓練結束。
AlexNet的TensorFlow實現
# -*- coding=UTF-8 -*- import tensorflow as tf # 輸入數據 import input_data mnist = input_data.read_data_sets("/tmp/data/", one_hot=True) # 定義網路超參數 learning_rate = 0.001 training_iters = 200000 batch_size = 64 display_step = 20 # 定義網路參數 n_input = 784 # 輸入的維度 n_classes = 10 # 標籤的維度 dropout = 0.8 # Dropout 的機率 # 占位符輸入 x = tf.placeholder(tf.types.float32, [None, n_input]) y = tf.placeholder(tf.types.float32, [None, n_classes]) keep_prob = tf.placeholder(tf.types.float32) # 卷積操作 def conv2d(name, l_input, w, b): return tf.nn.relu(tf.nn.bias_add( \ tf.nn.conv2d(l_input, w, strides=[1, 1, 1, 1], padding='SAME'),b) \ , name=name) # 最大下採樣操作 def max_pool(name, l_input, k): return tf.nn.max_pool(l_input, ksize=[1, k, k, 1], \ strides=[1, k, k, 1], padding='SAME', name=name) # 歸一化操作 def norm(name, l_input, lsize=4): return tf.nn.lrn(l_input, lsize, bias=1.0, alpha=0.001 / 9.0, beta=0.75, name=name) # 定義整個網路 def alex_net(_X, _weights, _biases, _dropout): _X = tf.reshape(_X, shape=[-1, 28, 28, 1]) # 向量轉為矩陣 # 卷積層 conv1 = conv2d('conv1', _X, _weights['wc1'], _biases['bc1']) # 下採樣層 pool1 = max_pool('pool1', conv1, k=2) # 歸一化層 norm1 = norm('norm1', pool1, lsize=4) # Dropout norm1 = tf.nn.dropout(norm1, _dropout) # 卷積 conv2 = conv2d('conv2', norm1, _weights['wc2'], _biases['bc2']) # 下採樣 pool2 = max_pool('pool2', conv2, k=2) # 歸一化 norm2 = norm('norm2', pool2, lsize=4) # Dropout norm2 = tf.nn.dropout(norm2, _dropout) # 卷積 conv3 = conv2d('conv3', norm2, _weights['wc3'], _biases['bc3']) # 下採樣 pool3 = max_pool('pool3', conv3, k=2) # 歸一化 norm3 = norm('norm3', pool3, lsize=4) # Dropout norm3 = tf.nn.dropout(norm3, _dropout) # 全連線層,先把特徵圖轉為向量 dense1 = tf.reshape(norm3, [-1, _weights['wd1'].get_shape().as_list()[0]]) dense1 = tf.nn.relu(tf.matmul(dense1, _weights['wd1']) + _biases['bd1'], name='fc1') # 全連線層 dense2 = tf.nn.relu(tf.matmul(dense1, _weights['wd2']) + _biases['bd2'], name='fc2') # Relu activation # 網路輸出層 out = tf.matmul(dense2, _weights['out']) + _biases['out'] return out # 存儲所有的網路參數 weights = { 'wc1': tf.Variable(tf.random_normal([3, 3, 1, 64])), 'wc2': tf.Variable(tf.random_normal([3, 3, 64, 128])), 'wc3': tf.Variable(tf.random_normal([3, 3, 128, 256])), 'wd1': tf.Variable(tf.random_normal([4*4*256, 1024])), 'wd2': tf.Variable(tf.random_normal([1024, 1024])), 'out': tf.Variable(tf.random_normal([1024, 10])) } biases = { 'bc1': tf.Variable(tf.random_normal([64])), 'bc2': tf.Variable(tf.random_normal([128])), 'bc3': tf.Variable(tf.random_normal([256])), 'bd1': tf.Variable(tf.random_normal([1024])), 'bd2': tf.Variable(tf.random_normal([1024])), 'out': tf.Variable(tf.random_normal([n_classes])) } # 構建模型 pred = alex_net(x, weights, biases, keep_prob) # 定義損失函式和學習步驟 cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(pred, y)) optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(cost) # 測試網路 correct_pred = tf.equal(tf.argmax(pred,1), tf.argmax(y,1)) accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32)) # 初始化所有的共享變數 init = tf.initialize_all_variables() # 開啟一個訓練 with tf.Session() as sess: sess.run(init) step = 1 # Keep training until reach max iterations while step * batch_size < training_iters: batch_xs, batch_ys = mnist.train.next_batch(batch_size) # 獲取批數據 sess.run(optimizer, feed_dict={x: batch_xs, y: batch_ys, keep_prob: dropout}) if step % display_step == 0: # 計算精度 acc = sess.run(accuracy, feed_dict={x: batch_xs, y: batch_ys, keep_prob: 1.}) # 計算損失值 loss = sess.run(cost, feed_dict={x: batch_xs, y: batch_ys, keep_prob: 1.}) print "Iter " + str(step*batch_size) + ", Minibatch Loss= " + "{:.6f}".format(loss) + ", Training Accuracy= " + "{:.5f}".format(acc) step += 1 print "Optimization Finished!" # 計算測試精度 print "Testing Accuracy:", sess.run(accuracy, feed_dict={x: mnist.test.images[:256], y: mnist.test.labels[:256], keep_prob: 1.}) 以上代碼忽略了部分卷積層,全連線層使用了特定的權重。