
樸素貝葉斯法是基於貝葉斯定理與特徵條件獨立假設的分類方法。
最為廣泛的兩種分類模型是決策樹模型(Decision Tree Model)和樸素貝葉斯模型(Naive Bayesian Model,NBM)。和決策樹模型相比,樸素貝葉斯分類器(Naive Bayes Classifier,或 NBC)發源於古典數學理論,有著堅實的數學基礎,以及穩定的分類效率。同時,NBC模型所需估計的參數很少,對缺失數據不太敏感,算法也比較簡單。理論上,NBC模型與其他分類方法相比具有最小的誤差率。但是實際上並非總是如此,這是因為NBC模型假設屬性之間相互獨立,這個假設在實際套用中往往是不成立的,這給NBC模型的正確分類帶來了一定影響。
基本介紹
- 中文名:樸素貝葉斯
- 外文名:Naive Bayesian Model
- 簡稱:NBM
- 屬於:廣泛的分類模型之一
定義,貝葉斯方法,樸素貝葉斯算法,算法原理,優缺點,優點,缺點,套用,文本分類,其他,
定義
貝葉斯方法
貝葉斯方法是以貝葉斯原理為基礎,使用機率統計的知識對樣本數據集進行分類。由於其有著堅實的數學基礎,葉斯分類算法的誤判率是很低的。貝葉斯方法的特點是結合先驗機率和後驗機率,即避免了只使用先驗機率的主管偏見,也避免了單獨使用樣本信息的過擬合現象。貝葉斯分類算法在數據集較大的情況下表現出較高的準確率,同時算法本身也比較簡單。
樸素貝葉斯算法
樸素貝葉斯算法(Naive Bayesian) 是套用最為廣泛的分類算法之一。
樸素貝葉斯方法是在貝葉斯算法的基礎上進行了相應的簡化,即假定給定目標值時屬性之間相互條件獨立。也就是說沒有哪個屬性變數對於決策結果來說占有著較大的比重,也沒有哪個屬性變數對於決策結果占有著較小的比重。雖然這個簡化方式在一定程度上降低了貝葉斯分類算法的分類效果,但是在實際的套用場景中,極大地簡化了貝葉斯方法的複雜性。
算法原理
樸素貝葉斯分類(NBC)是以貝葉斯定理為基礎並且假設特徵條件之間相互獨立的方法,先通過已給定的訓練集,以特徵詞之間獨立作為前提假設,學習從輸入到輸出的聯合機率分布,再基於學習到的模型,輸入 求出使得後驗機率最大的輸出
求出使得後驗機率最大的輸出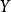 。
。
設有樣本數據集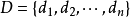 ,對應樣本數據的特徵屬性集為
,對應樣本數據的特徵屬性集為 類變數為
類變數為 ,即
,即 可以分為
可以分為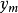 類別。其中
類別。其中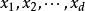 相互獨立且隨機,則
相互獨立且隨機,則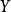 的先驗機率
的先驗機率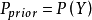 , 的後驗機率
, 的後驗機率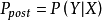 ,由樸素貝葉斯算法可得,後驗機率可以由先驗機率 、證據
,由樸素貝葉斯算法可得,後驗機率可以由先驗機率 、證據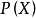 、類條件機率
、類條件機率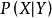 計算出:
計算出:
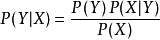
樸素貝葉斯基於各特徵之間相互獨立,在給定類別為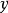 的情況下,上式可以進一步表示為下式:
的情況下,上式可以進一步表示為下式:
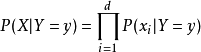
由以上兩式可以計算出後驗機率為:

由於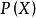 的大小是固定不變的,因此在比較後驗機率時,只比較上式的分子部分即可。因此可以得到一個樣本數據屬於類別
的大小是固定不變的,因此在比較後驗機率時,只比較上式的分子部分即可。因此可以得到一個樣本數據屬於類別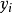 的樸素貝葉斯計算如下圖所示:
的樸素貝葉斯計算如下圖所示:
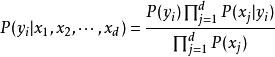
優缺點
優點
樸素貝葉斯算法假設了數據集屬性之間是相互獨立的,因此算法的邏輯性十分簡單,並且算法較為穩定,當數據呈現不同的特點時,樸素貝葉斯的分類性能不會有太大的差異。換句話說就是樸素貝葉斯算法的健壯性比較好,對於不同類型的數據集不會呈現出太大的差異性。當數據集屬性之間的關係相對比較獨立時,樸素貝葉斯分類算法會有較好的效果。
缺點
屬性獨立性的條件同時也是樸素貝葉斯分類器的不足之處。數據集屬性的獨立性在很多情況下是很難滿足的,因為數據集的屬性之間往往都存在著相互關聯,如果在分類過程中出現這種問題,會導致分類的效果大大降低。
套用
文本分類
分類是數據分析和機器學習領域的一個基本問題。文本分類已廣泛套用於網路信息過濾、信息檢索和信息推薦等多個方面。數據驅動分類器學習一直是近年來的熱點,方法很多,比如神經網路、決策樹、支持向量機、樸素貝葉斯等。相對於其他精心設計的更複雜的分類算法,樸素貝葉斯分類算法是學習效率和分類效果較好的分類器之一。直觀的文本分類算法,也是最簡單的貝葉斯分類器,具有很好的可解釋性,樸素貝葉斯算法特點是假設所有特徵的出現相互獨立互不影響,每一特徵同等重要。但事實上這個假設在現實世界中並不成立:首先,相鄰的兩個詞之間的必然聯繫,不能獨立;其次,對一篇文章來說,其中的某一些代表詞就確定它的主題,不需要通讀整篇文章、查看所有詞。所以需要採用合適的方法進行特徵選擇,這樣樸素貝葉斯分類器才能達到更高的分類效率。
其他
樸素貝葉斯算法在文字識別, 圖像識別方向有著較為重要的作用。 可以將未知的一種文字或圖像,根據其已有的分類規則來進行分類,最終達到分類的目的。
現實生活中樸素貝葉斯算法套用廣泛,如文本分類,垃圾郵件的分類,信用評估,釣魚網站檢測等等。
