)")
超鏈分析是將情報學中的“引文索引”思想引入網頁排名,根據網站受歡迎程度評價其質量。超鏈分析是一種引用投票機制,對於靜態網頁或者網站主頁,它具有一定的合理性,因為這樣的網頁容易根據其在網際網路上受到的評價,產生不同的超鏈指向量,超鏈分析的結果可以反映網頁的重要程度,從而給用戶提供更重要、更有價值的搜尋結果。
基本介紹
- 中文名:超鏈分析
- 外文名:Hypertext Link
- 功能:對網路連結的自身屬性、連結對象、連結網路等各種現象進行分析
- 主要算法:PageRank算法和HITS算法
- 套用:網路爬行和檢索結果排序
- 所屬領域:計算機科學技術
簡介,主要思想,主要算法,套用領域,存在缺陷,
簡介
超鏈分析的基本原理是:在某次搜尋的所有結果中,被其他網頁用超鏈指向得越多的網頁,其價值就越高,就越應該在結果排序中排到前面。使用超鏈分析技術,除要分析索引網頁本身的文字,還要分析索引所有指向該網頁的連結的URL和Anchor Text,甚至連結周圍的文字。
超鏈分析是一種引用投票機制,對於靜態網頁或者網站主頁,它具有一定的合理性,因為這樣的網頁容易根據其在網際網路上受到的評價產生不同的超鏈指向量,超鏈分析的結果可以反映網頁的重要程度,從而給用戶提供出更重要、更有價值的搜尋結果。
超鏈分析能夠極大地提高檢索結果的相關性,以至於幾乎所有的WEB搜尋引擎都宣稱他們使用了超鏈分析技術。超鏈分析的套用很廣泛,主要用於網路爬行和檢索結果排序。
主要思想
超鏈分析主要利用數學(主要是統計學和拓撲學)和情報學方法,對網路連結的自身屬性、連結對象、連結網路等各種現象進行分析,以便揭示其數量特徵和內在規律的一種研究方法。在超鏈分析中,常將web看成一個有向圖進行研究,用G=(V,E)表示,其中:
(1)V:由網頁構成的節點集合,p,q∈V,p≠q;
(2)E:由網頁間的超連結構成的有向邊集合:p→q∈E;
(3)p→q:節點p有一條超連結指向q,其中,p為q的鏈入網頁,稱為鏈源,a為p的鏈出網頁,稱為鏈宿;
(4)出鏈:p指向其它節點的超連結;
(5)入鏈:其它節點指向p的超連結;
(6)F(p):節點p所指向的節點集合;
(7)B(p):指向p的節點集合;
(8)節點出度:節點的出鏈數量;
(9)節點入度:節點的入鏈數量;
可以這樣考慮連結p→q的意義:網頁p告訴那些已經訪問了網頁p的用戶,他們可以沿著網頁p所創建的超連結對網頁q進行訪問。這樣兩個網頁之間的超連結可能表明p和q兩者具有相關的興趣主題。p→q表明p對q內容的某種程度的認可:可以說,超連結是p承認q權威性的一種方法。事實上,這個超連結給q的內容提供了某種評價,而這種評價是q的作者沒法控制的。
這樣,網頁作者通過連結的創建和指向選擇,為用戶提供了有價值的信息引導,使他們能夠訪問到與原網頁主題相關的其它網路資源。這是一個對網頁進行評論的自然過程。通過對web圖進行觀察,節點間存在著類似引文分析的關係:
(1)p,q,s∈V,如果p→q,q→s,則有p→→s存在,表示可傳遞(Transitive)關係,表示網路瀏覽過程中,可以沿著超連結在不同網頁間穿梭訪問。
(2)p,q,s∈V,如果p→s,且q-s,則p和q具有耦合關係(Coupling),耦合度越大,相關性也越大。
(3)p,q,s∈V,如果s→p,且s→q,則p和q具有同引關係(Co-Citation),同引度越大,相關性也越大。
主要算法
超鏈分析算法建立在兩個假設之上:①兩個網頁間存在連結關係表示兩個網頁之間內容相關;②如果兩個網頁存在連結關係,那么表明一個網頁的作者認為另一個網頁是有價值的。PageRank算法和HITS算法是其中兩種影響相當廣泛的算法,並在實際中得到了實現和使用。
(1)基於隨機衝浪模型的PageRank算法
PageRank算法最早由L·Page和S·Brinls為Google原型所提出的一種與查詢無關的算法。該算法將超鏈分析的兩個假設進行了引中,並作為其基本思想:①如果一個頁面被多次連結,則這個頁面很可能是重要的;②如果一個頁面儘管沒有被多次連結,但被一個重要頁面連結,則這個頁面很可能是重要的;③一個頁面的重要性被均勻分配,並被傳遞給所有它所連結的頁面。
PageRank計算網頁A權威度的公式:
公式說明:
①PRn(A):網頁A的PageRank值。
②PRn-1(Ti):網頁Ti存在指向A的連結,並且網頁Ti在上一次疊代時的PageRank值。
③C(Ti):網頁Ti的外鏈數量。
④d:阻尼係數,0<d<1,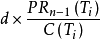 表示在隨機衝浪模型中網頁Ti將自身d的份額的PageRank值平均分給每個外鏈。由於網頁Ti指向網頁A,因此網頁A獲得來自網頁T的C(Ti)分之一的PageRank值。
表示在隨機衝浪模型中網頁Ti將自身d的份額的PageRank值平均分給每個外鏈。由於網頁Ti指向網頁A,因此網頁A獲得來自網頁T的C(Ti)分之一的PageRank值。
阻尼係數d的引入是為了降低了這個機率。阻尼係數d定義為用戶不斷隨機點擊連結的機率,所以,它取決於點擊的次數,被設定在0和1之間。d的值越高,連續點擊連結的機率就越大。因此,用戶停止順鏈點擊並隨機衝浪至另一頁面的機率在公式中用常數(1-d)表示,這也就是頁面本身所具有的權威值。
(2)基於中心——權威的HITS算法
HITS算法最早由Kleinberg在參與IBM的Clever項目時提出的一種依賴於查詢的超鏈分析算法。該算法的基本思想是:①權威(authority)網頁和中心(hub)網頁的概念,權威網頁是被大量超連結所指向的網頁,中心網頁本身未必具有權威性,但卻包含了多個指向權威網頁的超連結的網頁;②權威網頁和中心網頁之間的依賴關係,一個好的中心網頁應該指向很多好的權威網頁,而一個好的權威網頁則應該被很多好的中心網頁所指向。
給定一個寬主題查詢Q,HITS算法的基本步驟為:
①用基於文本內容檢索的搜尋引擎進行查詢,從返回結果集合中提取排序分值最高的一組(通常為200個)網頁構成一個根集R(root set);
②將R中的網頁的鄰接網頁(指向R中網頁的網頁,以及R中網頁所指向的網頁,最多為50個)包含進來,使根集合擴展為基集B(base set);
③從B中導出主題子圖,G[B]=(V,E);
④疊代計算直到收斂,對於所有V∈V,其權威值為a(v),中心值為h(v)。每次疊代後需要對a(v)和h(v)進行規範化處理:
⑤將計算結果中,排列中心值前n位的網頁和排列權威值的前n位的網頁作為結果輸出,n∈[5,10]。
套用領域
(1)指導網頁採集
一般的爬行器是根據網頁之間的連結信息來採集網頁,不考慮網頁質量的好壞。如果只想採集高質量的網頁,就要按照網頁質量的高低依次來進行採集,使得儘可能多地獲得高質量的網頁。網頁連結分析為判斷網頁的質量提供一種手段。搜尋引擎Google就是充分利用PageRank算法來提高Google爬行器的爬行性能。
(2)輔助結果排序
當用戶向搜尋引擎提交查詢式的時候,搜尋引擎返回的結果及其排序依賴於查詢式處理器和搜尋引擎所使用的算法。從用戶的角度看,希望將最相關、最重要的結果放在前面。採用超鏈分析的排序我們稱之為“連通性排名”(Connectivity-Based Ranking)。連通性排名可以分為查詢獨立模式(Query Independent Schemes)和查詢依賴模式(QueryDependent Schemes),前者使用的是著名的PageRank算法,後者使用的是HITS算法。
(3)檢索結果聚類
目前搜尋引擎的搜尋結果還不能令人滿意。因為用戶在提交一個查詢式的時候,返回的結果可能屬於不同的領域,而用戶一般關注的只是其中一個領域。考慮這種情況,有些學者向利用超鏈分析理論對檢索結果進行聚類,將聚類後的結果提供給用戶來瀏覽。
(4)查找相關網頁
在Web環境中則可以充分挖掘超鏈結構來查找相關網頁。查找相關網頁也稱為根據實例查找(QBE),它是根據用戶已經發現的Web網頁實例,找出與之相關的網頁。傳統算法需要將待分析的網頁下載到本地才能夠進行分析、計算,而基於超鏈分析的算法則可以不用下載和分析網頁的文本內容,完全利用相關超鏈數據來計算出相關網頁。該方法的意義在於它可以在很大程度上減少網頁的下載量,從而減輕網路負擔,最主要的是為用戶提供了一種新的信息獲取途徑和方法,如果與傳統的算法結合,則可以在很大程度上提高計算相關網頁的速度和精度。
(5)識別Web社區
通過網站、網頁間的關係以及某些訪問行為,確定一定的虛擬網路團體,找出這種團體,並分析其目的、行為、特徵、趨勢等。
(6)確定Web影響因子
這是一個新鮮的概念,它來自於期刊的影響因子的啟發,通過分析被鏈入(Link-in)數量、連結來源、鏈出(Link-out)數量等確定網站或網頁的影響力和重要程度。
存在缺陷
用戶在搜尋關於某些內容的有效信息時,最大的特點是各異性。利用超鏈分析技術,用戶將接受一種根據某種標準進行網頁排名的信息服務,從而演變成為各網站想盡辦法追求網頁排名的商業活動。
海量的網頁被收集回來,用姓名、電話、單位名稱或網名都可以搜尋到許多含有此關鍵字的信息,這些信息有不少侵權、侵犯隱私、泄露機密的信息,尤其是大量論壇的貼子被收錄,不少貼子言論含有攻擊的成分。所以如何及時處理掉這些連結又是搜尋引擎急需解決的問題。
