近鄰傳播算法(AP)是近年出現的一種在數據挖掘領域極具競爭力的聚類算法,相比較於傳統聚類算法,AP算法能夠在較短時間內完成大規模多類別數據集的聚類,且該算法能夠很好地解決非歐空間問題。因此,AP算法自提出以來,受到了廣泛的關注和套用
基本介紹
- 中文名:近鄰傳播算法
- 外文名:Affinity Propagation
基本信息,算法描述,算法分析,優點,缺陷,改進,
基本信息
2007年,Frey和Dueck在《Science》上首次提出了近鄰傳播算法,能夠在較短的時間內處理大規模數據集,得到較理想的結果。該方法是一種基於實例的方法(Instance-based),與經典的k-means算法具有相同的目標函式,但其在算法原理上與k-means算法存在很大的不同。近鄰傳播算法是一種基於近鄰信息傳遞的聚類算法,該算法以數據集的相似度矩陣作為輸入,算法起始階段將所有的樣本看作是潛在的聚類中心點,同時,將每個樣本點都視為網路中的一個節點,吸引力信息沿著節點連線遞歸傳輸,直到找到最優的類代表點集合(類代表點必須是實際數據集中的點,成exemplar),使得所有數據點到最近的類代表點的相似度之和最大。其中,吸引力信息是數據點適合被選作其他數據的類代表點的程度。
相比較於其他傳統的聚類算法,AP算法將每個數據點都作為候選的類代表點,避免了聚類結果受限於初始類代表點的選擇,同時該算法對於數據集生成的相似度矩陣的對稱性沒有要求,並在處理大規模多類數據時運算速度快,所以能夠很好地解決非歐空間問題(如不滿足對稱性或三角不等式)以及大規模稀疏矩陣計算問題等。
算法描述
下面詳細介紹AP算法的數學模型。
令數據集X={x1,x2,……,xn},設在數據的特徵空間中存在一些比較緊密的聚類C={C1,C2,……,Ck}。每個數據點對應且僅對應一個聚類,令xc(i)表示任意點xi對應的聚類代表點,i=1,2,……,N。則定義聚類的誤差函式為:

AP算法的目標就是尋找最優類代表點集合,使得誤差函式最小。即

算法首先將數據集的所有N個樣本點都視為候選的聚類中心,為每個樣本點建立與其它樣本點的吸引程度信息,即任意2個樣本點和之間的相似度。這種相似性可以根據所研究問題而具體設定,在實際套用中,不需要滿足歐式空間約束。傳統的聚類問題中,相似性通常被設定為兩點歐氏距離平方的負數:

s(i,j) 被存儲在相似度矩陣中,表示數據點在多大程度上適合作為數據點的類代表點。點對距其較近的點吸引程度更大,如果處於簇中心,則對其他數據點的吸引力之和較大,成為聚類中心的可能性也越大;如果在簇的邊緣,則對其他點的吸引力之和較小,成為聚類中心的可能性也較小。在聚類之前,算法為每個數據點設定其偏向參數s(i,j)。s(i,j)的值越大,相應的點被選中作為類代表點的可能性也就越大。算法通常假設所有樣本點被選中成為類代表點的可能性相同,即設定所有s(i,j)為相同值p。這是AP算法中的一個重要參數,p值的大小將影響到最終得到聚類的個數,因為p越大,越多的數據點傾向於成為最終的類代表點,則最終輸出的聚類數目越大,反之,如果p越小,則最終輸出的聚類數目就越小。因此,AP算法可以通過改變p值來尋找合適的類的數目。 參數p的取值對聚類性能的影響
參數p的取值對聚類性能的影響
參數p的取值對聚類性能的影響圖顯示了不同的p值對聚類結果的影響。
圖可以看出,p值越大,聚類數目越大,當p趨近於-1時,幾乎每個點都作為單獨的一類而被輸出。圖中,p在取值接近相似度中值附近([100,-10]),輸出正確的聚類數目3。所以,一般情況下,將p設為相似度矩陣中的相似度均值:

 信息量傳播示意圖
信息量傳播示意圖AP算法的疊代過程就是這兩個信息量交替更新的過程,算法初始階段,r(i,j)和a(i,j)都設為0,兩個信息的更新過程如下:
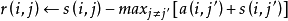


另外算法在信息更新時引入了另一個重要的參數l,成為阻尼因子。在每一個循環疊代中,r(i,j)和a(i,j)的更新結果都是由當前疊代過程中更新的值和上一步疊代結果加權得到的,目的是避免疊代過程中出現數值震盪。加權更新公式如下:
其中,0<=l<=1,默認值為0.5,阻尼因子的作用是改進收斂性,當AP算法在疊代過程中產生的類書不斷發生震盪而不能收斂時,增大l可消除這種震盪。
圖中表示的是r(i,j)和a(i,j)兩個信息在任意兩點之間相互傳播的過程,直到算法收斂,輸出三個最優類代表點,並形成以類代表點為中心的三個聚類。其中類代表點對應於數據集中的點。
算法分析
相比於k-means和k-中心算法,AP算法的最佳化過程具有更高的魯棒性。前兩種算法都是採用的貪婪算法來解決組合最佳化問題,AP算法是一種連續最佳化的過程,每個樣本點都被視為候選類代表點,聚類是逐漸被識別出來的。尤其是,AP算法不受初始點選擇的困擾,而且能夠保證收斂到全局最優。實際中,AP算法能獲得比k-means更穩定的結果。
AP算法和譜聚類都是基於數據的相似矩陣進行聚類的,由於AP算法對數據的相似矩陣的對稱性沒有任何要求,因此,AP算法比譜聚類算法適用範圍要廣,這也是AP算法一大優點。
由於近鄰傳播算法只需要進行簡單的局部計算,因此,與傳統聚類算法相比,它能夠在更短的CPU運算時間裡達到更好的聚類效果。當數據集規模較小時,近鄰傳播算法與傳統算法的差別不大,優勢不明顯;但是當數據集規模增大時,或者說,聚類算法的特徵矩陣變得高維稀疏時,近鄰傳播算法性能明顯優於傳統算法。目前該算法已經成功套用於人臉識別,基因發現、網路文本挖掘、圖像分割以及最優航線設計等領域。
優點
不需要事先指定聚類數目,在數據集的元素個數大於900時,相對其他同類算法其優勢 特別明顯,因此 AP算法非常適合於中大規模的數據聚類問題。
缺陷
AP算法仍然存在兩個主要缺陷:
1)AP算法只適合處理緊緻的超球形結構的數 據聚類問題,當數據集分布鬆散或結構複雜時,該算法不能給出理想的聚類結果;
2)AP算法是一種無監督的學習方法,不能直接適用於有約束條件的聚類問題。
改進
AP算法在運算的過程中追求誤差函式J(C)最小化,對於緊緻的聚類結構算法能夠在保證J(C)比較小的同時給出準確的聚類結果;但是當數據的聚類結構比較鬆散時,為了保證J(C)的最小化,容易產生局部的聚類,導致劃分的類數過多而使聚類結果不夠準確。另一方面,Frey和Dueck發表在《Science》的工作中,對於人工工具以及人臉圖像識別的例子採用了歐氏距離作為算法的相似度度量,該度量方法以數據點之間的絕對距離衡量數據之間的相似性,因此受數據集的形狀和密度的影響比較大。
不久,Givoni和Frey又在文獻中《A binary variable model for affinity propagation》,《Semi-Supervised Affinity Propagation with Instance-Level constraints》給出了圖像處理中有關非歐空間相似性的計算方法:

或者

其中,公式(1)中和分別代表圖像中心和圖像的視窗參數,公式(2)中代表圖像和滿足特定匹配的特徵個數,但是由於這種定義的相似性度量存在套用領域的局限性,因此該方法不適合在其他數據挖掘相關領域中推廣。
Michele等人為了使AP算法能夠處理環形數據,在文獻《Clustering by soft-constraint affinity propagation:Applications to gene-expression data》中提出了軟約束的AP算法。引入了一個軟參數β,使得算法在鬆弛條件下聚類,允許類代表點在該類之外,相應的目標函式為:

其中,Z憑經驗確定。此後不久,Michele又在文獻《Unsupervised and semi-supervised clustering by message passing:soft-constraint affinity propagation》中給出了一種半監督的軟約束AP算法,利用先驗信息指導AP聚類過程。這兩種算法雖然有效解決了環形數據聚類,但是依然不適合其他非凸形數據集聚類問題。
為了提高算法處理大規模數據集的速度,Cyril等人在文獻《Scaling Analysis of Affinity Propagation》中將BP神經網路與AP結合,提出了層次的AP算法(Hierarchical Affinity Propagation,HAP),該算法能夠在略低於甚至不低於原始AP算法精度的情況下,大大提高算法速度。文獻《Flow Transformation of Anonymous Communication Based on Hierarchical Weighted Affinity Propagation Clustering》中,Chong等人在該算法的基礎上提出了一種帶權重的層次AP算法(Hierarchical Weighted Affinity Propagation,HWAP),進一步提高了算法速度,但同時也帶來了算法精度的下降。
為了提高AP算法聚類的準確性,王開軍等人在文獻《自適應仿射傳播聚類》中提出了自適應仿射傳播聚類算法,討論了如何正確選擇疊代次數和阻尼因子,使算法在任何情況下都能自適應的收斂,但依然局限於超球形緊緻數據集聚類問題。肖宇等人在文獻《基於近鄰傳播算法的半監督聚類》中提出了一種基於近鄰傳播的半監督聚類算法,利用成對約束信息調整相似度矩陣,一定程度上改善了聚類性能,但其沒有考慮無標記樣本數據所隱含的背景信息,當約束信息較少或者包含噪聲時,反而可能誤導聚類過程。董俊等人在文獻《可變相似性度量的近鄰傳播聚類》中提出了可變相似性度量的近鄰傳播聚類算法,對於比較緊密和部分重疊的數據集,均可以給出較好的聚類結果,但是算法在密度不均勻或比較鬆散的數據集上不能得到理想的結果。
儘管對 AP算法進行研究的相關文獻不少,但大多集中在對於算法本身的改進及套用,而對於 AP算法相關算法細節的研究還較少。
