
增量學習是指一個學習系統能不斷地從新樣本中學習新的知識,並能保存大部分以前已經學習到的知識。增量學習非常類似於人類自身的學習模式。因為人在成長過程中,每天學習和接收新的事物,學習是逐步進行的,而且,對已經學習到的知識,人類一般是不會遺忘的。
基本介紹
- 中文名:增量學習
- 外文名:Incremental Learning
- 領域:人工智慧
背景介紹,表現和套用,特點和意義,特點,意義,常見的增量式學習框架,自組織增量學習神經網路,情景記憶馬爾可夫決策過程,
背景介紹
人工智慧的參照樣本始終沒有離開人類本身。而終身式、增量式的學習能力是人類最重要的能力之一。機器人如果能像人類一樣對環境以及任務進行增量的學習,這使得機器人終身學習成為可能。增量學習思想的重要性體主要在2個方面:
(1)在實際的感知數據中,數據量往往是逐漸增加的,因此,在面臨新的數據時,學習方法應能對訓練好的系統進行某些改動,以對新數據中蘊涵的知識進行學習;
(2)對一個訓練好的系統進行修改的時間代價通常低於重新訓練一個系統所需的代價。
增量學習思想可以描述為:每當新增數據時,並不需要重建所有的知識庫,而是在原有知識庫的基礎上,僅對由於新增數據所引起的變化進行更新。我們發現,增量學習方法更加符合人的思維原理。增量學習框架有很多,各框架最核心的內容是處理新數據與已存儲知識相似性評價方法。因為該方法決定覺察新知識並增加知識庫的方式,它影響著知識的增長。新知識的判定機制才是增量學習的核心部件。
(1)在實際的感知數據中,數據量往往是逐漸增加的,因此,在面臨新的數據時,學習方法應能對訓練好的系統進行某些改動,以對新數據中蘊涵的知識進行學習;
(2)對一個訓練好的系統進行修改的時間代價通常低於重新訓練一個系統所需的代價。
增量學習思想可以描述為:每當新增數據時,並不需要重建所有的知識庫,而是在原有知識庫的基礎上,僅對由於新增數據所引起的變化進行更新。我們發現,增量學習方法更加符合人的思維原理。增量學習框架有很多,各框架最核心的內容是處理新數據與已存儲知識相似性評價方法。因為該方法決定覺察新知識並增加知識庫的方式,它影響著知識的增長。新知識的判定機制才是增量學習的核心部件。
表現和套用
增量學習主要表現於兩個方面:一方面由於其無需保存歷史數據,從而減少存儲空間的占用;另一方面增量學習在當前的樣本訓練中充分利用了歷史的訓練結果,從而顯著地減少了後續訓練的時間。
增量學習主要有兩方面的套用:一是用於資料庫非常大的情形,例如Web日誌記錄;二是用於流數據,因為這些數據隨著時間在不斷的變化,例如股票交易數據.另外在增量學習中,現有的增量學習算法大多採用決策樹和神經網路算法實現的,它們在不同程度上具有以下兩方面的缺點:一方面由於缺乏對整個樣本集期望風險的控制,算法易於對訓練數據產生過量匹配;另一方面,由於缺乏對訓練數據有選擇的遺忘淘汰機制,在很大程度上影響了分類精度。
最簡單的方法之一是增量學習存儲的所有數據允許重新訓練。在另一個極端是數據的訓練、一個實例接一個實例,一個流行的線上學習。採用線上學習算法的方法已經實現增量學習但沒有考慮所有的學習問題,特別是學習的新類。
特點和意義
特點
隨著人工智慧和機器學習的發展,人們開發了很多機器學習算法。這些算法大部分都是批量學習(Batch Learning)模式,即假設在訓練之前所有訓練樣本一次都可以得到,學習這些樣本之後,學習過程就終止了,不再學習新的知識。然而在實際套用中,訓練樣本通常不可能一次全部得到,而是隨著時間逐步得到的,並且樣本反映的信息也可能隨著時間產生了變化。如果新樣本到達後要重新學習全部數據,需要消耗大量時間和空間,因此批量學習的算法不能滿足這種需求。只有增量學習算法可以漸進的進行知識更新,且能修正和加強以前的知識,使得更新後的知識能適應新到達的數據,而不必重新對全部數據進行學習。增量學習降低了對時間和空間的需求,更能滿足實際要求。雖然增量學習的研究已經有一定的歷史,但由於不同的作者對其理解不同,而且增量學習也沒有統一的定義。許多作者甚至將增量學習等同於線上學習(Online Learning)。這裡,引用Robipolikar對增量學習算法的定義,即一個增量學習算法應同時具有以下特點:
1)可以從新數據中學習新知識;
2)以前已經處理過的數據不需要重複處理;
3)每次只有一個訓練觀測樣本被看到和學習;
4)學習新知識的同時能保存以前學習到的大部分知識;
5)—旦學習完成後訓練觀測樣本被丟棄;
6)學習系統沒有關於整個訓練樣本的先驗知識;
意義
開展增量學習的研究具有以下兩方面非常重要的意義:
1)隨著資料庫以及網際網路技術的快速發展和廣泛套用,社會各部門積累了大量數據,而且這些數據量每天都在快速增加。如何從這些數據中獲取有用信息以及對數據進行分析和處理是一項艱苦的工作。而傳統的批量學習方式是不能適應這種需求的,只有通過增量學習的方式才能有效解決這種需求。
2)通過對增量學習模型的研究,能夠使我們從系統層面上更好地理解和模仿人腦的學習方式和生物神經網路的構成機制,為開發新計算模型和有效學習算法提供技術基礎。
常見的增量式學習框架
自組織增量學習神經網路
自組織增量學習神經網路(SOINN)是一種基於競爭學習的兩層神經網路。SOINN的增量性使得它能夠發現數據流中出現的新模式並進行學習,同時不影響之前學習的結果。因此SOINN能夠作為一種通用的學習算法套用於各類非監督學習問題中。
SOINN是兩層結構(不包括輸入層)的競爭性神經網路,它以自組織的方式對輸入數據進行線上聚類和拓撲表示,其工作過程如圖一所示。
SOINN是兩層結構(不包括輸入層)的競爭性神經網路,它以自組織的方式對輸入數據進行線上聚類和拓撲表示,其工作過程如圖一所示。
- 第1層網路接受原始數據的輸入,以線上的方式自適應地生成原型神經元來表示輸入數據。這些節點和它們之間的連線反映了原始數據的分布情況;
- 第2層根據第1層網路的結果估計出原始數據的類間距離與類內距離,並以此作為參數,把第1層生成的神經元作為輸入再運行一次SOINN算法,以穩定學習結果。
如圖二所示:當輸入數據存在多個聚類並存在噪聲時,SOINN依然能夠生成可靠的神經元節點來表示輸入數據中的各個聚類;同時子圖的拓撲結構反映了原始數據分布的性。 圖一
圖一
圖一 圖二
圖二動態調整是SOINN實現自組織和增量學習的關鍵,它使得神經元的權值向量和網路的拓撲結構能夠隨著輸入模式的到來動態地進行調整,以最佳化對輸入數據的表達精度。此外,通過適時增加神經元不僅能夠自適應地確定神經元的數量以滿足一定的量化誤差約束,同時還能在不影響之前學習結果的情況下適應之前沒有學習過的輸入模式。
情景記憶馬爾可夫決策過程
情景記憶馬爾可夫決策過程EM-MDP準確來說是一套完整的人工智慧方案(簡化版),這個框架中包括對情景的認知、增量學習、短期與長期記憶模型。我們將焦點放在框架中的增量學習部分。該框架基於自適應共振理論(ART)與稀疏分布記憶(SDM)的思想實現對情景記憶序列的增量式學習。SDM是計算機科學家彭蒂.卡內爾瓦於1974年提出的能夠將思維所擁有的任何感知存入有限記憶機制的方法。這樣,在學習過程中,每次可有多個狀態神經元同時被告激活,每個神經元均可看成一類相近感知的代表。相比SOINN網路每次最多只能有一個輸出節點,該方法具有環境適應性好的優點。
情景記憶網路學習模型的構建基於EM-MDP模型框架,由感知輸入(O層)、感知相似性度量(U層)、狀態神經元(S層)和輸出情景記憶(E層)組成,其結構模型如圖三所示。框架中U層與S層都具有增量式學習的能力,U層與S層的結構如圖四所示。U層節點個數等於輸入感知的維數,每個節點的輸出由3個信號共同確定:(1)當前環境的感知輸入 ;(2)控制信號
;(2)控制信號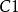 ;(3)由S層反饋的獲勝狀態神經元的映射感知。
;(3)由S層反饋的獲勝狀態神經元的映射感知。 圖三
圖三
情景記憶網路學習模型的構建基於EM-MDP模型框架,由感知輸入(O層)、感知相似性度量(U層)、狀態神經元(S層)和輸出情景記憶(E層)組成,其結構模型如圖三所示。框架中U層與S層都具有增量式學習的能力,U層與S層的結構如圖四所示。U層節點個數等於輸入感知的維數,每個節點的輸出由3個信號共同確定:(1)當前環境的感知輸入
圖三U層節點的輸出u根層這3個信號採用“多數表決2/3”原則計算獲得。當 ,反饋映射感知信號為0時,U層節點輸出由輸入感知決定,即
,反饋映射感知信號為0時,U層節點輸出由輸入感知決定,即 。當反饋映射感知信號不為0,
。當反饋映射感知信號不為0, 時,U層節點輸出取決於輸入感知與反饋映射感知的比較情況,如果相似性度量大於閾值,則對感知向量學習進行調整,否則增加新的感知
時,U層節點輸出取決於輸入感知與反饋映射感知的比較情況,如果相似性度量大於閾值,則對感知向量學習進行調整,否則增加新的感知 。S層有m個節點,用以表示m個狀態神經元,該狀態神經元空間可通過增加新的神經元節點進行動態增長。狀態神經元間具有權值,代表情景記憶的連線關係。
。S層有m個節點,用以表示m個狀態神經元,該狀態神經元空間可通過增加新的神經元節點進行動態增長。狀態神經元間具有權值,代表情景記憶的連線關係。
 圖四
圖四情景網路接受來自環境的感知輸入,通過檢查當前感知輸入與所有存儲感知向量之間的匹配程度,確定新感知及其相關事件是否已存在機器人的情景記憶當中。按照預先設定的激活閾值來考察相似性度量,決定對新輸入的感知採取何種處理方式。在網路每一次接受新的感知輸入時,都需要經過一次匹配過程。相似性度量存在兩種情況:
- 相似度超過設定閾值,則選擇該鄰近狀態集為當前輸入感知的代表狀態神經元集合。感知通過學習進行調整以使其之後遇到與當前輸入感知接近的感知時能獲得更大的相似度,對非該鄰近狀態集,感知向量不做任何調整。實際上是對情景記憶中的映射感知進行重新編碼,以穩定已經被學習了的熟悉事件。
- 相似度不超過設定閾值,需要在S層新增一個代表新輸入感知的狀態神經元並存儲當前感知為該新增狀態的映射感知,以便參加之後的匹配過程。同時建立與該狀態神經元相連的權值,以存儲該類感知和參與以後的匹配過程。實際上是對不熟悉事件建立新的表達編碼。
