UCT算法(Upper Confidence Bound Apply to Tree),即上限置信區間算法,是一種博弈樹搜尋算法,該算法將蒙特卡洛樹搜尋(Monte—Carlo Tree Search,MCTS)方法與UCB公式結合,在超大規模博弈樹的搜尋過程中相對於傳統的搜尋算法有著時間和空間方面的優勢。
基本介紹
- 中文名:上限置信區間算法
- 外文名:Upper Confidence Bound Apply to Tree
- 別稱:樹圖置信算法
- 提出者:Levente Kocsis與Csaba Szepesvári
- 提出時間:2006
- 套用學科:計算機科學
- 適用領域範圍:計算機博弈
提出,研究現狀,基本思想,樹內選擇策略,預設仿真策略,仿真結果回傳,算法優勢,套用,領域發展,深藍——蠻算硬漢,浪潮天梭——以一敵五,沃森——全才學霸,
提出
早些年.計算機博弈對於棋類遊戲的研究集中在基於模式識別和專家系統的方法上(最典型的是基於靜態評估函式的僅一B博弈樹方法),並在西洋棋、中國象棋等項目中獲得了成功。但是對於圍棋類的項目,傳統的方法一直無法取得滿意的結果。在2000年前後,世界上最高水平的計算機圍棋軟體的棋力還比不上人類的業餘初段。
圍棋作為一種特殊的完備信息博弈,由於其本身的非完備特性,也成為了蒙特卡羅方法套用的載體之一。但是,由於圍棋的複雜度高,且極具欺騙性,對電腦程式提出了巨大的挑戰。為了處理如此眾多的可能情況,人工智慧專家已經設計出一些算法,來限制搜尋的範圍,但它們都無法在大棋盤的比賽中戰勝實力稍強的人類棋手。2006年秋季,兩位匈牙利研究人員報告了一種新算法,它的勝率比現有最佳算法提高了5%,能夠在小棋盤的比賽中與人類職業棋手抗衡。這種被稱為UCT(UpperConfidenceboundsappliedtoTrees)的算法,是匈牙利國家科學院計算機與自動化研究所(位於布達佩斯)的列文特·科奇什(LeventeKocsis)與加拿大阿爾伯塔大學(UniversityofAlberta,位於埃德蒙頓)的喬鮑·塞派什瓦里(CsabaSzepesvári)合作提出的,是著名的蒙特卡羅方法(MonteCarlomethod)的擴展套用。
研究現狀
法國南巴黎大學的數學家西爾萬·熱利(SylvainGelly)與巴黎技術學校的王毅早(YizaoWang,音譯)將UCT集成到一個他們稱之為MoGo的程式中。該程式的勝率竟然比先前最先進的蒙特卡羅擴展算法幾乎高出了一倍。2007年春季,MoGo在小棋盤的比賽中擊敗了實力強勁的業餘棋手,在大棋盤比賽中也擊敗了實力稍弱的業餘棋手,充分展示了能力。熱利認為UCT易於實現,並有進一步完善的空間。科奇什預言,10年以後,計算機就能攻克最後的壁壘,終結人類職業棋手對圍棋的統治。
哈工大深圳研究生院智慧型計算中心也是國內最早探索非完備信息博弈的機構之一。經過3年的研究,已經取得了一定成功,並在此基礎上開發了一套擁有完整人機互動界面並具有較強智慧型水平的四國軍棋博弈系統。
基本思想
由於圍棋有很大的分支系 數(BranchingFactor),傳統搜尋技術一直沒有在計算機圍棋領域取得有意義的成果 ,2006 年 UCT算法改變了 這種 局 面。UCT算 法是一種特殊的蒙特卡洛搜尋算法,它由樹內選擇策略、預設仿真策略和仿真結果回傳三部分組成。
樹內選擇策略
如圖 1所示, 傳統搜尋技術都有搜尋深度 d 這個參數. 當搜尋達到深度d 時, 搜尋算法從評估函式取得評估值, 而搜尋算法負責找到讓評估值最大的分支。 這種在同一深度 d 獲取評估值的方式, 讓搜尋深度d, 分支係數 b,與搜尋樹葉子節點數 N 的關係為 N =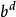 。 UCT 算法與傳統搜尋技術的最大區別在於不同的分支可以有不同的搜尋深度, 如圖 2 所示。 UCT 算法在不同的深度獲取評估值. 對於最有“ 希望”求解問題的分支, UCT 算法的搜尋深度可以很深( 遠大於 d), 而對於“ 希望” 不大的分支, 其搜尋深度可以很淺( 遠小於 d) 。 當最有“希望”求解問題的分支數量遠少於“ 希望” 不大的分支數量時, UCT 算法就可以把搜尋資源有效地用於最有“希望”求解問題的分支, 從而獲得比傳統搜尋算法更深的有效深度 d′。這個具有神奇力量的“希望”是由樹內選擇策略計算的.
。 UCT 算法與傳統搜尋技術的最大區別在於不同的分支可以有不同的搜尋深度, 如圖 2 所示。 UCT 算法在不同的深度獲取評估值. 對於最有“ 希望”求解問題的分支, UCT 算法的搜尋深度可以很深( 遠大於 d), 而對於“ 希望” 不大的分支, 其搜尋深度可以很淺( 遠小於 d) 。 當最有“希望”求解問題的分支數量遠少於“ 希望” 不大的分支數量時, UCT 算法就可以把搜尋資源有效地用於最有“希望”求解問題的分支, 從而獲得比傳統搜尋算法更深的有效深度 d′。這個具有神奇力量的“希望”是由樹內選擇策略計算的.
從根節點開始, 對於每一個非葉子節點 n的孩子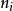 ∈ ch( n) , 樹內選擇策略計算一個評估值
∈ ch( n) , 樹內選擇策略計算一個評估值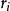 , 並根據 值選擇一個孩子節點進行下一步選擇, 直到到達葉子節點。 如果當前節點為最大節點( Max Node) 時, 樹內選擇策略選擇 值最大的孩子進行下一步選擇; 如果當前節點為最小節點( Min Node) 時, 樹內選擇策略選擇 值最小的孩子進行下一步選擇。 的計算公式是:
, 並根據 值選擇一個孩子節點進行下一步選擇, 直到到達葉子節點。 如果當前節點為最大節點( Max Node) 時, 樹內選擇策略選擇 值最大的孩子進行下一步選擇; 如果當前節點為最小節點( Min Node) 時, 樹內選擇策略選擇 值最小的孩子進行下一步選擇。 的計算公式是: 圖1 α-β剪枝
圖1 α-β剪枝 圖2 UCT算法
圖2 UCT算法
從根節點開始, 對於每一個非葉子節點 n的孩子
圖1 α-β剪枝圖2 UCT算法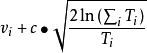
式中: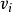 是以節點 為根節點的子樹的所有仿真結果的平均值, 反映了根據目 前仿真結果觀測到的節點 能提供的回報值的期。
是以節點 為根節點的子樹的所有仿真結果的平均值, 反映了根據目 前仿真結果觀測到的節點 能提供的回報值的期。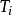 是節點 的訪問次數, 也是節點 被樹內選擇策略選中的次數。
是節點 的訪問次數, 也是節點 被樹內選擇策略選中的次數。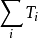 是節點 n 的訪問次數。c 是一個手工設定的常數。 c 的作用是平衡 UCT 算法的利用需求(exploitation)和探索需求( exploration)。
是節點 n 的訪問次數。c 是一個手工設定的常數。 c 的作用是平衡 UCT 算法的利用需求(exploitation)和探索需求( exploration)。
預設仿真策略
當搜尋到達葉子節點時, UCT 算法執行擴展操作( Expansion): 把此葉子節點允許的所有合法下一步產生的子節點, 作為新的葉子節點加入到搜尋樹中, 並正確初始化其 v 值和 T 值。 UCT 算法並沒有使用額
外的評估函式來獲取新葉子節點的評估 v 值, 而是使用預設仿真策略來繼續搜尋直到遊戲進入結束狀態。此時, 棋盤上每一個位置都有明確的歸屬, 黑方贏還是白方贏可以很容易地計算出 來. 葉子結點的評估值就是當黑方勝時為 1, 白方贏為 0。 最簡單的預設仿真策略就是在所有的合法下一步中, 均勻地隨機選擇下一步。 用隨機策略作為預設仿真策略產生的程式棋力不高, 因此大多數棋力不錯的程式都採用了更加複雜的預設仿真策略。 這些實際使用的預設仿真策略, 考慮了氣( liberty ) 、形(pattern ) 、定式( joseki ) 、攻擊模式
( attack patterns ) 、防守模式( defense patterns ) 等一些重要的圍棋基本概念。 此外, 為了獲得更加可靠的評估值, 每次到達葉子結點, UCT 算法可以使用 k 次仿真的平均結果作為評估 v 。 k 的值可以是幾百或者幾千。
外的評估函式來獲取新葉子節點的評估 v 值, 而是使用預設仿真策略來繼續搜尋直到遊戲進入結束狀態。此時, 棋盤上每一個位置都有明確的歸屬, 黑方贏還是白方贏可以很容易地計算出 來. 葉子結點的評估值就是當黑方勝時為 1, 白方贏為 0。 最簡單的預設仿真策略就是在所有的合法下一步中, 均勻地隨機選擇下一步。 用隨機策略作為預設仿真策略產生的程式棋力不高, 因此大多數棋力不錯的程式都採用了更加複雜的預設仿真策略。 這些實際使用的預設仿真策略, 考慮了氣( liberty ) 、形(pattern ) 、定式( joseki ) 、攻擊模式
( attack patterns ) 、防守模式( defense patterns ) 等一些重要的圍棋基本概念。 此外, 為了獲得更加可靠的評估值, 每次到達葉子結點, UCT 算法可以使用 k 次仿真的平均結果作為評估 v 。 k 的值可以是幾百或者幾千。
仿真結果回傳
當葉子節點通過仿真獲得新的 v 值和 T 值時, UCT 算法通過結果回傳更新搜尋路徑上的所有內部節
點( internal nodes ) 的 v 值和 T 值. 其公式為:
點( internal nodes ) 的 v 值和 T 值. 其公式為:
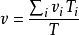
即父節點的訪問次數 T是所有子節點訪問次數 之和, 觀測回報值 v 是所有子節點觀測回報值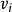 的加權平
的加權平
均, 權值為子節點被訪問的比例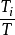 . 結果回傳從葉子節點開始, 沿搜尋路徑逐級向上更新, 直到根節點。
. 結果回傳從葉子節點開始, 沿搜尋路徑逐級向上更新, 直到根節點。
均, 權值為子節點被訪問的比例
算法優勢
一、UCT 的工作模式是時間可控的
我們可以在算法執行過程中的任何時間突然終止算法,UCT 算法可以返回一個差不多理想的結果。當然如果給與更為充分的時間的話,算法結果會非常逼近實際的最優值。但是這一點在 alpha-beta 搜尋中是絕對行不通的。圖 3-3 展現了如果我們突然中斷 alpha-beta 搜尋程式,某些處於根節點之下的第一層的節點都還沒有被計算,這樣的結果時此時 alpha-beta 搜尋程式的返回結果很有可能和實際地最優解相去甚遠。而圖 3-2 是一個典型的中斷時的 UCT 搜尋樹的情況,我們可以通過兩幅圖片的比較看出 UCT 算法的時間可控性的原因。當然,傳統的搜尋算法也有一些最佳化策略來增加其時間可控性,例如設定初始化搜尋深度。但不可否認的是,UCT 的任意時間終止特性更加強大,這可以使它在套用於特定的博弈系統中的時候能夠非常方便的控制走步產生的最大時間。這是傳統的搜尋算法所無法比擬的。
二、UCT 具有更好的魯棒性
這是因為它使用一種平滑的方式處理搜尋過程中的不確定性。在每個節點,其計算值取決於它的搜尋節點序列上的所有子節點的計算值,其值是一個經過平滑的最大值的估計值。這樣,由於每個子節點的計算過程都經過重新的抽樣計算,不會因為個別嚴重偏離事實的抽樣結果而對最終的結果產生致命性的影響。同時,由於算法在確定計算的節點序列時,依賴於第一層子節點的估值以及該估值的可信度。也就是說,如果某一個子節點有一個遠大於其他子節點的估值,那么相對於其他節點,它就有機會更為頻繁的被搜尋和計算,UCT 算法對這個“最大值”節點會進行最為頻繁的搜尋。在非完備信息博弈問題的條件下,與蒙特卡羅抽樣算法相結合的 UCT 算法中,頻繁的搜尋意味著頻繁的抽樣,而大量的抽樣次數正式保證估計值能夠儘量逼近真值的唯一途徑。同時,如果有兩個子節點擁有相近的估值並大於其他節點,那么 UCT 算法會均衡的對兩個節點進行搜尋。這樣的搜尋方式有一個優勢,那就是 UCT 算法最後的作為搜尋結果的節點以及次優節點一定是經過多次抽樣的具有較高估值可信度的節點。
三、 在 UCT 搜尋算法的過程中,博弈樹以一種非對稱的形式動態擴展出來
這樣做有兩個好處。首先,傳統的博弈樹擴展方式,仍然以 alpha-beta搜尋樹為例,每向下擴展一層都意味著博弈書規模的指數型增長以及搜尋時間的指數型增加。對於記憶體和 CPU 性能都有限的個人電腦來說,這一問題有的情況下是致命的。而在 UCT 算法搜尋過程中,每次對於更深一層的擴展僅局限於搜尋序列的最後一個節點。這樣的 UCT 算法可以在擴展節點的同時不斷的動態釋放計算過的節點記憶體,使得算法運行的時間複雜性和空間複雜性可以被更好的控制。其次,正因為上述特性,對於較好的作為被選候補的節點,算法往往可以進行更為深入的搜尋,這點可以在圖一中體現出來,同時,這種非對稱性擴展完全是在算法的執行過程中自動進行的。因此,和傳統的博弈樹算法相比較,UCT算法有著其獨有的優勢,特別是當博弈樹規模非常大的時候。UCT算法首次套用的圍棋博弈系統,以及本文即將討論的四國軍棋博弈系統都屬此例。因此,UCT搜尋算法在本系統中的使用是切合實際的。
套用
2006年第一個基於UCT算法的圍棋程式MoGo在9×9棋盤上達到了專業棋手的水平。
2009年8月基於UCT的開源程式Fuego在9×9棋盤上戰勝了周俊勛九段。
2012年6月計算機圍棋程式Zwn19S在19×19棋盤上達到了KGS的6段評級。
2013年3月圍棋軟體CrazyStone在受讓四子的情況下。戰勝日本棋手石田芳夫九段,其棋力已達到業餘五、六段的水平。
領域發展
深藍——蠻算硬漢
1997年,美國超級計算機“深藍”以2勝1負3平戰勝了當時世界排名第一的西洋棋大師卡斯帕羅夫。“深藍”的運算能力當時在全球超級計算機中居第259位,每秒可運算2億步。
在今天看來,“深藍”還算不上足夠智慧型,主要依靠強大的計算能力窮舉所有路數來選擇最佳策略:“深藍”靠硬算可以預判12步,卡斯帕羅夫可以預判10步,兩者高下立現。
比賽中,第二局的完敗讓卡斯帕羅夫深受打擊,他的鬥志和體力在隨後3局被拖垮,在決勝局中僅19步就宣布放棄。
浪潮天梭——以一敵五
2006年,中國超級計算機“浪潮天梭”同時迎戰柳大華、張強、汪洋、徐天紅、朴風波5位中國象棋特級大師。在2局制的博弈中,浪潮天梭以平均每步棋27秒的速度,每步66萬億次的棋位分析與檢索能力,最終以11:9的總比分險勝。
張強坦承:“以往和人比賽,到了最後時刻就是意志和心態的對決了,看誰能堅持到最後,誰能不犯錯誤。但是計算機沒有這樣的問題。”
從那場比賽開始,象棋軟體蓬勃發展,人類棋手逐漸難以與之抗衡。
沃森——全才學霸
2011年,“深藍”的同門師弟“沃森”在美國老牌智力問答節目《危險邊緣》中挑戰兩位人類冠軍。雖然比賽時不能接入網際網路搜尋,但“沃森”存儲了2億頁的數據。“沃森”可以在3秒內檢索數百萬條信息並以人類語言輸出答案,還能分析題目線索中的微妙含義、諷刺口吻及謎語等。“沃森”還能根據比賽獎金的數額、自己比對手落後或領先的情況、自己擅長的題目領域來選擇是否要搶答某一個問題。“沃森”最終輕鬆戰勝兩位人類冠軍,展示出的自然語言理解能力一直是人工智慧界的重點課題。
