
基本介紹
- 中文名:分布分析法
- 外文名:distributional analysis
- 所屬學科:數學(統計學),語言學
- 別稱:統計學中也稱“直方圖法”
統計學術語,定義,基本介紹,語言學術語,定義,基本介紹,
統計學術語
定義
在生產工作正常的情況下,產品的質量也不可能完全相同,但也不會相差太大,而是圍繞著一定的平均值,在一定的範圍內變動和分布。分布分析法就是通過對質量的變動分布狀態的分析中發現問題的一種重要方法。它可以了解生產工序是否正常,廢品是否發生等情況。其工具是直方圖,故又稱直方圖法。
基本介紹
分布分析法又稱直方圖法。它是將蒐集到的質量數據進行分組整理,繪製成頻數分布直方圖,用以描述質量分布狀態的一種分析方法。在學習直方圖之前,我們首先應了解一下質量數據的一些特點。
1. 質量數據
質量管理的指導思想中有一條是“用數據說話”。每一種產品都有其質量特性。為了儘量準確地表達產品的質量特性,就需要量化這些特性,從而得到了質量特性值。產品的質量特性有很多都是可以直接衡量的,比如重量、長度、強度、濃度、速度等;但是另一些特性卻很難直接衡量,如光潔度、造型美感、舒適性、味感等,這些特性要確定一些技術參數來間接反映。也有一些特性值雖是可以直接衡量,為了方便而選用代用值去間接衡量,如耐用度是金屬切削工具的真正質量特性,而規定的硬度HRC是代用特性。總之,產品的質量特性絕大部分是以量的形式表示,可以據此制定質量標準。
常用到的質量特性數值有五類:
計量值數據:指可以連續取值的數據,可以出現小數,小數位數根據要求而定,即數據具有連續性,像長度、重量、溫度、壓力、化學成分等。
計數值數據:指不能連續取值的數據,只能以件數、個數、點數等整數計量,具有離散性。
評分數:有些質量特性值既可為整數值又可為非整數值,如舒適度、美感度等,只是為了方便起見,常將這些數定義為計數值,即只取整數。
順序數:只能排出順序的數,多取整數。
優劣值(或等級數):只能定出優劣程度,表示等級。
2.直方圖
直方圖又稱質量分布圖。它是通過對收集來的數據進行加工、整理,以此來判斷生產過程質量水平及不合格品率大小的一種常用工具。根據直方圖可掌握產品質量的波動情況,了解質量特徵的分布規律,以便對質量狀況進行分析判斷。
繪製直方圖一般需要50個以上數據,通過以下步驟進行。
蒐集整理數據:用隨機抽樣的方法抽取數據,一般要求數據在50個以上。
計算極差R:極差R是數據中最大值和最小值之差。
對數據分組:包括確定組數、組距和組限。
第一,確定組數K。確定組數的原則是分組的結果能正確地反映數據的分布規律。組數應根據數據多少來確定。組數過少,會掩蓋數據的分布規律;組數過多,使數據過於零亂分散,也不能顯示出質量分布狀況。一般可參考表1的經驗數值確定。
數據總數N | 分組數K |
50~100 | 6~10 |
100~250 | 7~12 |
250以上 | 10~20 |
第二,確定組距H。組距是組與組之間的間隔,即一個組的範圍。各組距應相等,於是有
極差≈組距×組數,即: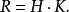
因而組數、組距的確定應根據極差綜合考慮,適當調整,還要注意數值儘量取整,使分組結果能包括全部變數值,同時也便於以後的計算分析。
第三,確定組限。每組的最大值為上限,最小值為下限,上、下限統稱組限。
確定組限時應注意使各組之間連續,即較低組上限應為相鄰較高組下限,這樣才能不致使有的數據被遺漏。對恰恰處於組限值上的數據,其解決的辦法有:規定每組上(或下)組限不計在該組內,而應計入相鄰較高(或較低)組內;將組限值較原始數據精度提高半個最小測量單位。
編制數據頻數統計表:統計各組頻數,可採用唱票形式進行,頻數總和應等於全部數據個數。
繪製頻數分布直方圖:在頻數分布直方圖中,橫坐標表示質量特性值,並標出各組的組限值。畫出以組距為底,以頻數為高的K個直方形,便得到頻數分布直方圖。
繪製出直方圖以後,將之與標準分布圖比較可以對該批產品質量分布情況作出一個判斷。
語言學術語
定義
分布分析法是結構主義語言學所採用的一種分析語言的方法。分析語言諸單位在語言結構中的分布關係,藉以進行語言單位的分類與歸納語言的結構系統。如分析音位在詞中,詞在句子中的分布情況。它用於音素、語素直到結構體的分析,並把分布分析歸納為切分話語、歸併語素、語素分類、語素組合四個步驟,用以揭示語音、語法和辭彙成分在較大的序列中的分布情況。這種方法首先由美國描寫語言學派提出來。
基本介紹
按照Harris的定義,一個單位的“分布”是指“它所出現的全部環境的總和,也就是這個單位的所有(不同的)位置(或者出現情況)的總和,這個單位出現的這些位置是同其他單位的出現有關係的”。分布分析最初被用於音位分析,後來則廣泛運用於語素分析和句法分析。美國結構主義語言學家賦予“分布”以特殊的地位,認為“描寫語言學的主要研究工作……就是要確立話語中某些部分或特徵的相互間的分布或配列關係”。這使得分布分析成為後布龍菲爾德學派最根本的語言分析方法,而分布的標準也成為該學派對語言進行切分和歸類時所遵循的主要標準,以至於有人把他們的語言分析思想稱作“分布主義”(distributionalism)。根據單位所出現的環境,分布可分為三種類型:
1)對等分布(equivalent distribution),即兩個成分可出現在相同的環境。如果這兩個成分相互替代時不改變整個形式的意義,則它們互為自由變體,如either中的/i:/和/ai/,以及湖北方言中的/n/和/l/;如果使意義發生改變,則兩個成分處於對立分布,如game中的/g/與came中的/k/;
2)部分對等分布,即兩個成分經常但並非總是出現於同一環境,如/k/與/ŋ/,前者可出現於詞首、詞中和詞尾,而後者不出現於詞首,但可以出現在詞中和詞尾;
3)互補分布,即兩個成分從不在同一環境中出現,如[t]與[th],在詞首的元音前只能出現送氣音[th],而在詞首的輔音/s/後只能出現不送氣音[t]。
分布分析則有兩種情況。一種情況是以尋找語言單位的同類(或部分同類)環境為原則的歸類法,在形式類的歸併中常用到這種分析方法,如Fries把凡能出現於(The)___is/are good或___s are/were good框架中的形式稱為I類詞。Hockett把能夠出現在cart、can go、can go there之前的she、he、it、I、we、they等歸為一個形式類。另一種情況是以尋找語言單位的異類環境為原則的歸類法,即根據互補分布來進行歸類,在音位和語素的歸併中常用到這種分析方法。如Harris把英語中的/-iz/、/-s/、/-z/、/-ən/(在ox後出現)、/a/~/e/(如man)和零形式(在sheep中出現)都歸併為一個語素(複數語素),因為它們具有相同的意義,且處於互補分布之中。
分布分析從語言的形式出發,著眼於易於觀察的語言單位之間的位置關係和它們所處的環境,因此避免了傳統語言學因過分依賴意義而導致分析中主觀性過強的缺陷。例如Harris便認為,採用分布分析的原因在於“方法嚴密的需要”(demand of rigor),同時也在於這種分析能處理某些用語義分析難以確定的情況。不過,以Harris為代表的某些後布龍菲爾德學派的學者,如Bloch、Trager等人,在語言分析中極力迴避意義,試圖完全依賴分布來對語言進行描寫。Bloch宣稱,可以“完全不依賴於意義”,而僅僅依靠語音特徵和分布來確定一種語言的音位系統。Trager&Smith也說:“意義沒有什麼指導作用,分析的理論基礎……在於發現類似的模式和序列出現的情況和分布。”Harris則認為,在語言分析中,意義的使用只能是“起提示作用”(heuristically),“決定性的標準永遠只能是用分布狀況予以說明”。然而,正如眾多學者所指出的,僅靠分布法是不可能對語言作出全面、準確的描寫和分析的。而且實際上,分布主義者在語言分析中還是利用了意義。另外,分布分析還存在理論上的循環論證、操作上的主觀性(如對環境的選擇)等缺陷,在實際套用中其操作程式也極為繁瑣。這些弊病在相當程度上限制了分布法的有效運用。
