
基本介紹
概述,PDB硬體結構,作用和目標,
概述
並行資料庫技術起源於20世紀70年代的資料庫機(Database Machine)研究,研究的內容主要集中在關係代數操作的並行化和實現關係操作的專用硬體設計上,希望通過硬體實現關係資料庫操作的某些功能,該研究以失敗而告終。80年代後期,並行資料庫技術的研究方向逐步轉到了通用並行機方面,研究的重點是並行資料庫的物理組織、操作算法、最佳化和調度策略。從90年代至今,隨著處理器、存儲、網路等相關基礎技術的發展,並行資料庫技術的研究上升到一個新的水平,研究的重點也轉移到數據操作的時間並行性和空間並行性上。
PDB硬體結構
PDB的硬體結構一般分為三類:共享記憶體(Shared-Memory,簡稱SM)、共享磁碟(Shared-Disk,簡稱SD)、無共享(Shared-Nothing,簡稱SN),如圖所示。
- SM結構又可稱為完全共享型(Share-Eveyrtihng),所有處理機存取一公共全局記憶體和所有磁碟,如IBM/370、VAX是其代表。
- SD結構中每個處理機有自己的私有記憶體,但能訪問所有磁碟,IBM的yS:plex和早期的VAx簇是其代表。
- SN結構中所有磁碟和記憶體分散給各處理機,每個處理機只能直接訪問其私有記憶體和磁碟,各自都是一個獨立的整體,處理機間由一公共互連網路連線,Teradata的DBC/1012、Tandem的Nonstop SQL是典型代表。
對這三種結構,長期以來人們爭論不休,直到近期才逐漸趨於一致,普遍認為PDB越來越趨向於Shared-Nothing的結構。這是因為在這樣的系統結構下,可望在複雜DB的查詢和在線上執程處理上達到線性加速比(Speedup)和伸縮比(Scaleup)。所謂加速比是指一定規模的任務在小規模系統和大規模系統上運行的時間之比,即:
加速比 = 小規模系統上運行時間 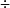 大規模系統上運行時間
大規模系統上運行時間
如果系統規模擴大了N倍,例如結點數增加了N倍後,加速比等於N,則稱作線性加速比。伸縮比是任務在小規模系統上運行時間與擴大N倍的任務在擴大N倍的系統上運行時間之比,即:
伸縮比 = 小任務在小系統上運行時間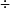 大任務在小系統上運行時間
大任務在小系統上運行時間
如果伸縮比等於1,則稱作線性伸縮比。
實際上影響接近線性加速比和線性伸縮比的主要因素有三個:啟動時間(這是啟動所有結點進行並行操作所必需的時間)、衝突(當多個結點競爭資源時所必需的等待時間)、負載不均(由於一個任務分成多個子任務並行執行,任務的處理時間應該是最慢的那個子任務的處理時間)。對於啟動時間與負載不均是三種結構的PDB所共同面臨的,而對於衝突,因為SN結構的處理機間沒有共享資源,因此沒有衝突或衝突最小,系統規模的擴充與縮小隻涉及結點的人網與出網,可伸縮性較好,從而容易適應不同套用的需要,這就是為什麼今天較為成功的PDB都是SN結構的原因。
熟悉分散式資料庫(DDB)的人們也許會覺得SN結構的PDB與DDB的硬體結構非常相似,因為DDB的硬體結構也是由網路連線若干台計算機而組成(見圖)。的確,物理上它們是十分相似的。但邏輯上PDB系統中的N個結點並不平等。其中只有一個結點與用戶接口,接受用戶請求.輸出處理結果,制定執行方案,而其餘結點只具有執行操作和彼此之間的通信能力,但不具備與用戶的互動能力。換句話說,PDB在邏輯上往往是有一個前台處理機和多個後台處理機結點模型的系統(圖)。我們把前台結點稱主結點,後台結點稱從結點,物理上主結點和從結點可以在一個物理結點上。而系統中的個結點從邏輯上講完全是平等的,他們沒有主次之分,即沒有控制整個系統的主機,也沒有受控於它機的從機。因此,主從控制計算機系統或分級控制計算機系統不是分散式系統`月’。由此可見,基於SN結構的PDB與DDB在系統的邏輯結構上是完全不同的。

作用和目標
性能指標關注的是並行資料庫系統的處理能力,具體的表現可以統一總結為資料庫系統處理事務的回響時間。並行資料庫系統的高性能可以從兩個方面理解,一個是速度提升(SpeedUp),一個是範圍提升(ScaleUp)。速度提升是指,通過並行處理,可以使用更少的時間完成兩樣多的資料庫事務。範圍提升是指,通過並行處理,在相同的處理時間內,可以完成更多的資料庫事務。並行資料庫系統基於多處理節點的物理結構,將資料庫管理技術與並行處理技術有機結合,來實現系統的高性能。
可用性指標關注的是並行資料庫系統的健壯性,也就是當並行處理節點中的一個節點或多個節點部分失效或完全失效時,整個系統對外持續回響的能力。高可用性可以同時在硬體和軟體兩個方面提供保障。在硬體方面,通過冗餘的處理節點、存儲設備、網路鏈路等硬體措施,可以保證當系統中某節點部分或完全失效時,其它的硬體設備可以接手其處理,對外提供持續服務。在軟體方面,通過狀態監控與跟蹤、互相備份、日誌等技術手段,可以保證當前系統中某節點部分或完全失效時,由它所進行的處理或由它所掌控的資源可以無損失或基本無損失地轉移到其它節點,並由其它節點繼續對外提供服務。
為了實現和保證高性能和高可用性,可擴充性也成為並行資料庫系統的一個重要指標。可擴充性是指,並行資料庫系統通過增加處理節點或者硬體資源(處理器、記憶體等),使其可以平滑地或線性地擴展其整體處理能力的特性。
隨著對並行計算技術研究的深入和SMP、MPP等處理機技術的發展,並行資料庫的研究也進入了一個新的領域,集群已經成為了並行資料庫系統中最受關注的熱點。目前,並行資料庫領域主要還有下列問題需要進一步地研究和解決。
(1)並行體系結構及其套用,這是並行資料庫系統的基礎問題。為了達到並行處理的目的,參與並行處理的各個處理節點之間是否要共享資源、共享哪些資源、需要多大程度的共享,這些就需要研究並行處理的體系結構及有關實現技術。
(2)並行資料庫的物理設計,主要是在並行處理的環境下,數據分布的算法的研究、資料庫設計工具與管理工具的研究。
(3)處理節點間通訊機制的研究。為了實現並行資料庫的高性能,並行處理節點要最大程度地協同處理資料庫事務,因此,節點間必不可少地存在通訊問題,如何支持大量節點之間訊息和數據的高效通訊,也成為了並行資料庫系統中一個重要的研究課題。
(4)並行操作算法,為提高並行處理的效率,需要在數據分布算法研究的基礎上,深入研究聯接、聚集、統計、排序等具體的數據操作在多節點上的並行操作算法。
(5)並行操作的最佳化和同步,為獲得高性能,如何將一個資料庫處理事務合理地分解成相對獨立的並行操作步驟、如何將這些步驟以最優的方式在多個處理節點間進行分配、如何在多個處理節點的同一個步驟和不同步驟之間進行訊息和數據的同步,這些問題都值得深入研究。
(6)並行資料庫中數據的載入和再組織技術,為了保證高性能和高可用性,並行資料庫系統中的處理節點可能需要進行擴充(或者調整),這就需要考慮如何對原有數據進行卸載、載入,以及如何合理地在各個節點是重新組織數據。
